
De digitale uitdagingen anno 2022 liegen er niet om. Enerzijds verwachten je klanten een perfecte online-ervaring, met minder nemen ze geen genoegen. Anderzijds was het nog nooit zo moeilijk om die ervaring te garanderen. Hoe pak je dit aan?
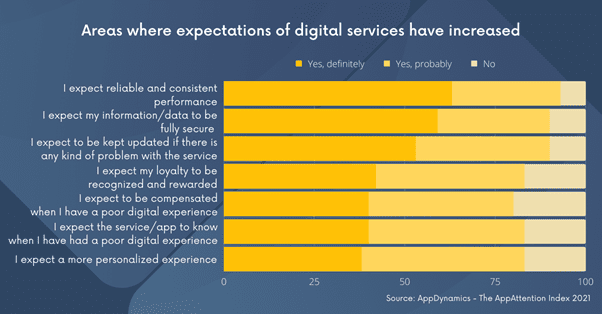
De pandemie heeft de adoptie van digitale diensten enorm versneld. Niet alleen de digitale tijdsbesteding nam toe, ook het aantal applicaties dat consumenten dagelijks gebruiken steeg met 30 procent de afgelopen 2 jaar. Hiermee stegen ook de verwachtingen van consumenten naar recordhoogte. 61 procent geeft aan dat zij geen slechte prestaties meer dulden. Er is altijd wel een alternatieve aanbieder. Als eigenaar van applicaties en digitale diensten, legt dit natuurlijk heel wat druk op je schouders.
Daarnaast ziet de typische IT-omgeving er vandaag helemaal anders uit dan pakweg 10 jaar geleden. Voorheen had je vaak te maken met een monolithisch opgezette structuur: voor elke dienst was er wel een andere infrastructuur. Als een dienst of toepassing uitviel, was het probleem vrij eenvoudig te vinden. Maar tegenwoordig is ons IT-landschap een complexe aaneenschakeling van verschillende diensten en toepassingen beheerd door verschillende leveranciers en vaak vanop verschillende locaties: on-site databases, remote file servers, clouddiensten, enzovoort.
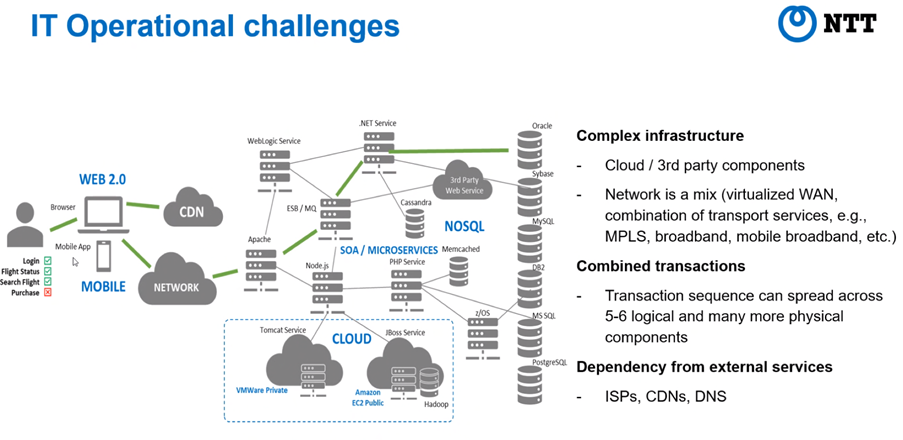
IT vandaag, complexiteit van de bovenste plank
Je moet het niet zover zoeken om een voorbeeld te vinden. Het uitvoeren van een peer-to-peer betaling, bij voorbeeld tussen een bloemist of anders bedrijf en zijn klant. Het lijkt in het eerste opzicht zeer eenvoudig. Maar het is een complexe aaneenschakeling van diensten en applicaties:
- De bloemist meldt zich aan bij de peer-to-peer payment app en specifieert het bedrag
- De P2P-provider bevestigt het bedrag
- De app creëert vervolgens een unieke id voor de betaling (bedrag en handelaar)
- Deze id, meestal een QR-code, kan hij delen met zijn klant
- De klant scant de QR-code in en de P2P-provider bevestigt dat er inderdaad een betaling open staat voor dit bedrag bij de handelaar in kwestie
- Vervolgens kan de betaling worden bevestigd aan de hand van een pincode
- Hierop geeft de P2P-provider deze bevestiging tot betaling door aan de bank van de klant
- De bank valideert de appprovider en controleert of er genoeg geld op de rekening staat
- Wanneer alles oké is, bevestigt de bank de betaling aan de P2P-provider
- De P2P-provider bevestigt de betaling aan de app
- De app geeft de betaling door aan de bloemist
- En aan beide kanten wordt de succesvolle betaling bevestigt.
Wanneer er hier iets fout loopt, is het niet zo simpel om snel de zere plek te vinden:
- Waarom werkt het niet en wat werkt er niet?
- Ligt het aan een slechte internetverbinding of de beschikbaarheid van de clouddienst?
- Is er een API-connectie die niet correct functioneert?
- Is de lokale of remote toepassing ontregeld door een upgrade?
- Enzovoort
Alle afzonderlijke tools voor elk onderdeel van de dienst of toepassing geven inzicht in het gedrag van hun specifieke componenten. Maar vaak is er geen overkoepelende monitoring. Als er dan iets fout gaat, zit er niets anders op dan het nog eens te proberen of een stel duurbetaalde specialisten samen in de kamer zetten. Het duurt dan uren of zelfs dagen voor het euvel is opgelost. En wanneer je bepaalde toepassingen host bij Microsoft Azure, Google of een andere clouddienst, heb je nog minder vat op de fout en hoe je deze kan lokaliseren en herstellen.
Met observability bewaar je het overzicht en krijg je grip op je IT-infrastructuur
Om je door deze stortvloed aan gegevens te navigeren en prestaties te contextualiseren, heb je extra tools nodig. IT-specialisten moeten kunnen observeren waar de oorzaak van het probleem zich bevindt en welke impact dit heeft op zowel klanten als je bedrijf zelf. Veeleer dan steeds de ene pleister na de andere op een open wonde te plakken. Zo moet je je niet steeds zorgen maken over ‘alle lichtjes die al dan niet op groen staan’. Deze kostbare tijd investeer je beter in innovaties en het optimaliseren van de customer experience.
Vandaag hebben IT-specialisten echter niet de nodige tools om technische problemen en de impact hiervan op de zakelijke context te identificeren.
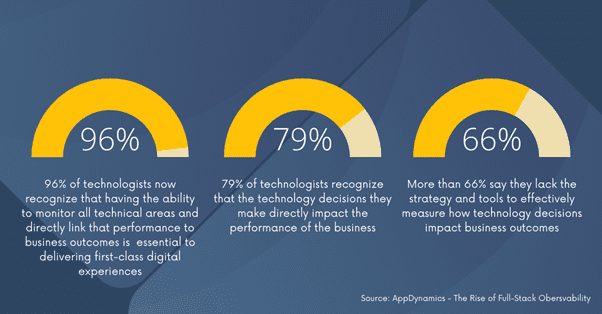
Uit onderzoek van AppDynamics, een bedrijf dat zich specialiseert in realtime application monitoring, blijkt dat 96 procent van IT-specialisten erkent dat het essentieel is om alle technische applicaties overkoepelend te kunnen monitoren om deze te koppelen aan business drivers. Enkel zo kunnen ze een first-class digitale ervaring aanbieden en de digitale transformatie versnellen. Daarnaast geeft 79 procent van de IT-specialisten aan dat de technologische beslissingen die zij nemen een rechtstreekse invloed hebben op de prestaties van het bedrijf. Maar meer dan 66 procent zegt dat ze niet de nodige strategie en tools hebben om effectief te meten hoe deze technologische beslissingen de bedrijfsresultaten beïnvloeden. Observability is hier de oplossing. Het zorgt ervoor dat IT-specialisten het overzicht houden over hun hele IT-park en de prestaties kunnen zien en begrijpen. Het laat hen toe processen te optimaliseren en de koppeling te maken met de bedrijfsresultaten.
Een eerste stap is om te kijken wat er al is. Welke monitoringtools gebruikt je al? Ten tweede is het belangrijk te weten waar je naar toe wil. Wat is je ideale scenario? Het zorgt ervoor dat je eventuele lacunes in de monitoring kan identificeren, maar ook dat er geen blind spots blijven. Je kan pas een goede observability opzetten wanneer je alle relevante componenten in kaart hebt gebracht.
Voorspellen, proactief ingrijpen en automatiseren: AIops to the rescue
Wanneer alles goed is geïmplementeerd, pluk je daar snel de vruchten van. En je kan eventueel een laag artificiële intelligentie toevoegen aan je observability-oplossing. Dan spreken we van AIOps. Artificiële intelligentie leert hoe je applicaties horen te werken om zo afwijkingen of zorgwekkende trends preventief te detecteren. Op deze manier kan je sneller de oorzaak definiëren en voorspellen welke impact dit mogelijk heeft op je infrastructuur, de diensten die hiervan gebruik maken en je eindgebruikers. Het vlot identificeren van de oorzaak van een probleem bespaart je heel wat werk. Het is net als bij de dokter: je pakt beter de oorzaak aan, dan elk symptoom afzonderlijk. Zo bespaar je heel wat tijd, maar voorkom je vooral geïrriteerde klanten die mogelijk afhaken.
Het lijkt een mooi plaatje dat ik hier schets, maar het is moeilijker te bereiken dan je zou denken. Je bent immers niet alleen afhankelijk van je eigen inspanningen, maar ook van wat leveranciers van SaaS- of cloud-toepassingen je bieden. En daar wringt soms het schoentje. Bouwers van SaaS-software zijn vaak allesbehalve bezig met het observable maken van hun software. Dat maakt het niet gemakkelijk om die specifieke toepassing op te nemen in je volledige observability. Softwareontwikkelaars zouden verplicht observability by design moeten hanteren als bouwprincipe, net zoals security by design. Maar daar zijn we helaas nog lang niet.

Dit is een ingezonden bijdrage van Lieven Stassen, Senior Intelligent Infrastructure Specialist bij NTT Ltd. Klik hier voor meer informatie over de oplossingen van het bedrijf.