
Als je de vraag in de titel aan Jensen Huang stelt, is het antwoord duidelijk ja. De CEO van Nvidia is dan ook eigenhandig verantwoordelijk voor de ontwikkeling van accelerated computing, waarbij de cpu plaats maakt voor de parallelle rekenkracht van gpu’s. Techzine kreeg de kans om in gesprek te gaan met de Nvidia-topman tijdens de recente GPU Technology Conference in Munchen.
“Moore’s Law is voorbij”, steekt Huang van wal. “De groei in processorkracht neemt nog maar drie procent per jaar toe. Accelerated computing is de nieuwe weg voorwaarts. Op tien jaar tijd hebben we met onze benadering de prestaties 1.000 keer verbeterd.”
In die tien jaar heeft Nivida evenveel iteraties van zijn CUDA-platform uitgebracht. CUDA staat voor Compute Unified Device Architecture. Het is een parallel computingplatform en programmeermodel dat het mogelijk maakt om gpu’s in te zetten voor algemene rekentaken. Ontwikkelaars schrijven hun algoritmes nog steeds in C, C++ of een andere compatibele programmeertaal die hen bekend is. Dankzij uitbreiding en aanpassing van de code, wordt de applicatie geprogrammeerd om optimaal gebruik te maken van het parallel rekenwerk van een gpu.
“Voor mij is een gpu geen graphics processing unit, maar een general parallel unit.”
Huang besefte naar eigen zeggen al bij de oprichting in 1993 dat Nvidia niet alleen groot kon worden met grafische kaarten voor gamers, maar dat het potentieel nog veel groter was. “We realiseerden ons toen al dat Nvidia de kans had om een echt groot computingbedrijf te worden. Voor mij is een gpu geen graphics processing unit, maar een general parallel unit.” Het zou evenwel nog veertien jaar duren voor het fundament van die visie werd gelegd met de release van CUDA 1.
Vandaag is CUDA 10 beschikbaar voor de ontwikkeling van gpu-versnelde applicaties. Deze versie is ontwikkeld voor gpu’s op de nieuwe Turing-architectuur van Nvidia, waarvan de eerste exemplaren afgelopen zomer verschenen. Turing betekent een grote sprong voorwaarts ten opzichte van de Pascal-architectuur en maakt voor het eerst realtime ray tracing mogelijk. “Het is de belangrijkste innovatie van Nvidia op het gebied van computer graphics in meer dan een decennium”, zegt Huang. “Op drie jaar tijd hebben we de prestaties vertienvoudigd.”
One trick pony
Die enorme prestatiewinst kan worden gerealiseerd omdat bij gpu-versnelling de hardware is geoptimaliseerd voor een specifieke taak. Een klassieke cpu is een general-purpose processor die via software allerlei soorten berekeningen kan uitvoeren. Dat gebeurt sequentieel. De cpu moet eerst een berekening helemaal afwerken voor hij aan de volgende kan beginnen. Een gpu is ontworpen om berekeningen parallel uit te voeren op hardware die daar speciaal voor is geoptimaliseerd. Die specifieke hardware-aanpak gaat logischerwijze sneller dan een software-aanpak op meer algemene hardware.
Met CUDA en Turing heeft Nvidia een algemeen platform en architectuur voor gpu-versnelling, maar de producten worden telkens aangepast aan de specifieke behoeften van een domein. “Accelerated computing richt zich op één domein tegelijk en op de volledige stack. Er worden nieuwe algoritmes, benaderingen en architecturen ontwikkeld”, vertelt Huang. De technologie van zijn bedrijf wordt vandaag onder meer gebruikt voor computer graphics, zelfrijdende auto’s, robotics, medische beeldvorming, wetenschappelijk onderzoek, machine learning en deep learning.
Lees dit: Huawei opent aanval op Nvidia met full-stack AI-portfolio
Op de vraag in welk van die markten Nvidia het meest investeert, heeft Huang meteen een gevat antwoord klaar: “We investeren 100% in maar één ding: accelerated computing. Het lijkt misschien niet zo, maar eigenlijk zijn we een one trick pony. We denken na over computing in geselecteerde markten, waar we zien dat er een groot gat is tussen de vraag naar en beschikbaarheid van rekenkracht. Waar de enige oplossing is om de volledige stack opnieuw te ontwerpen, van de applicatie tot de chip.”
Data science democratiseren
In Munchen ging de aandacht in het bijzonder naar de versnelling van machine en deep learning, met de lancering van het nieuwe Rapids-platform. “Deep learning heeft de manier waarop we software maken veranderd. Artificiële intelligentie betekent dat niet langer de mens, maar software nieuwe software schrijft. Dat vraagt om een andere bouw van computers en accelerated computing is daar een succesvolle versie van”, meent Huang. Met Rapids en de nieuwde DGX-2-hardware versnelt Nvidia de volledige data science stack.
“Het versnellen van data science voor machine learning is belangrijk. Het is vandaag de grootste markt in high-performance computing en wordt in alle industrieën toegepast. Alle bedrijven willen data-driven zijn om competitief te blijven”, vertelt Huang. Snelheid is daarbij volgens de Nvidia-CEO geen doel op zich, maar biedt rechtstreekse voordelen. “We democratiseren machine learning en deep learning door de rekentijd te verminderen.”
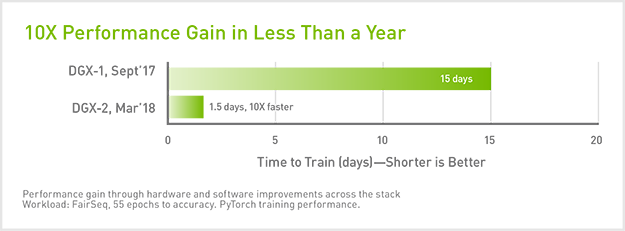
Gpu-versnelling levert eerst en vooral een aanzienlijke tijdswinst op. Eén DGX-2 verpakt 16 gpu’s met een gezamenlijke computerkracht van 2 petaFLOPS. Dat is goed voor tien keer betere prestaties dan de DGX-1 van vorig jaar. Een trainingsperiode waar de DGX-1 15 dagen voor nodig heeft, doorloopt de DGX-2 op anderhalve dag.
Eén DGX-2 biedt volgens Nvidia evenveel rekenkracht als een door cpu’s aangedreven data science cluster van 300 servers, ter waarde van 3 miljoen dollar. Maar dan aan slechts een achtste van de kostprijs, achttien keer lager stroomverbruik en op een vijftiende van de fysieke oppervlakte. De vergelijking is een beetje scheef, maar maakt de voordelen meteen duidelijk. Door niet alleen de hardware, maar de hele stack te blijven optimaliseren, gaan de prestaties van gpu-versnelde systemen elk jaar met rasse schreden vooruit.
Fundamenteel verschil
“Het fundamentele verschil met Moore’s Law, is dat die wet uitsluitend op cpu-prestaties berust om software sneller te maken. Accelerated computing kijkt naar de hele stack. Niet alleen de chips, maar ook de algoritmes. Het doel is om de applicatie sneller te maken, niet de processor. Dat is een verschillend doel”, besluit Huang. “Het geeft je meer vrijheid en opent je verbeelding voor nieuwe oplossingen, waaronder ook het versnellen van de chips.”