
Nvidia lanceert het open source GPU-acceleratieplatform Rapids tijdens zijn GPU Technology Conference in Mà¼nchen. Bedrijven kunnen aan de slag met het platform voor data science en machine learning om sneller enorme hoeveelheden data te analyseren. Zo kunnen ze sneller en accurater businessvoorspellingen maken dan met CPU’s mogelijk is.
“Dit is een logische stap voor Nvidia”, zegt Jeff Tseng, die de AI-inspanningen van de chipfabrikant overziet. “We hebben een architectuur die ontworpen is om met grote hoeveelheden data om te gaan.” Daarmee verwijst hij naar de parallelle rekenkracht van GPU’s, die zich veel beter leent voor big data analytics en machine learning dan de sequentiële rekenkracht van CPU’s.
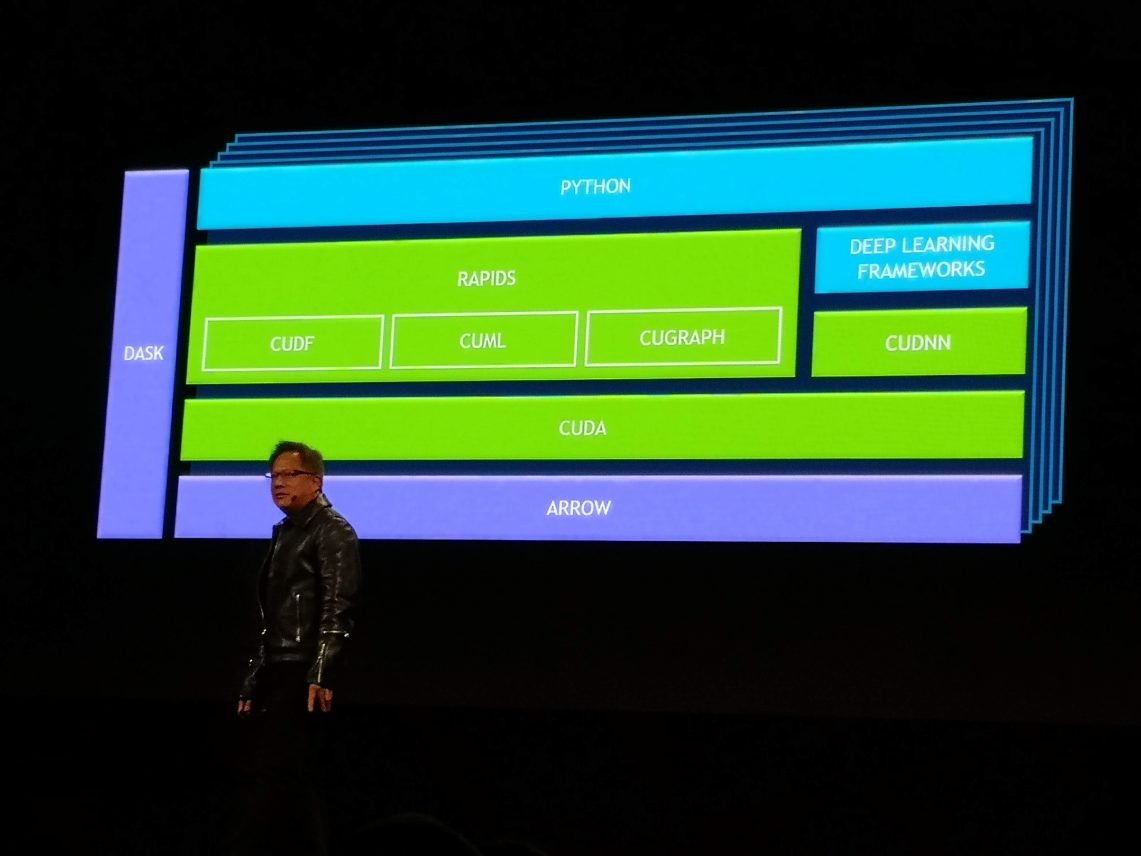
Rapids omvat open source libraries voor GPU-versnelde analytics, machine learning en binnenkort ook datavisualisatie. Voor het eerst kan de volledige data science pipeline op GPU’s worden uitgevoerd. Dat biedt een enorme boost in prestaties voor het tackelen van complexe businessuitdagingen, zoals het voorspellen van creditcardfraude, inventory forecasting en het beter begrijpen van koopgedrag.
50 keer sneller
“Waar het met CPU-systemen afhankelijk van de dataset uren tot dagen kan duren om modellen voor machine learning voor te bereiden, kunnen we met Rapids dat proces zelfs tot minuten herleiden”, vertelt Tseng. Initiële benchmarks op een Nvidia DGX-2-systeem tonen tot 50 keer snellere prestaties.
Die snellere prestaties zijn niet zomaar Nvidia die even met de spieren rolt, maar leveren ook concrete businessvoordelen op. Tseng illustreert het met een simpel voorbeeld van een supermarkt die zijn waren elke paar dagen slecht ziet worden. Een overschot aan voorraad kost veel geld en betekent dat eten wordt verspild. Te weinig voorraad betekent dat de supermarkt klanten verliest. Met inventory forecasting kan de supermarkt zijn nodige voorraad voorspellen aan de hand van data.
“Bij inventory forecasting worden tientallen datapunten verzameld. Die data moet worden opgeschoond en voorbereid voor gebruik in een machinelearningmodel, dat vervolgens nog moet worden getraind. Met een CPU-systeem duurt dat proces algauw enkele dagen, maar met GPU-versnelling wordt het ingekort tot enkele uren. De kruidenier kan zo veel sneller en accurater beslissingen maken over zijn stock.”

Open source
Het Rapids-platform is gebouwd op CUDA en volledig open source. De code wordt beschikbaar gemaakt onder de Apache-licentie. Naast individuele libraries, worden ook containerversies van Rapids aangeboden voor deployment in de cloud.
De software integreert naadloos met de populairste open source data science libraries en frameworks, zoals Apache Spark. Nvidia heeft de populairste python en machine learning libraries genomen – waaronder Apache Arrow, Pandas en scikit-learn – en daar GPU-versnelling aan toegevoegd.
De groene chipreus werkt samen met verschillende partners in de open source communities om het aantal compatibele libraries nog verder uit te breiden.
Early adopters
Nvidia heeft reeds enkele toonaangevende enterprises aangetrokken die als early adopters met Rapids aan de slag zijn gegaan. HPE gebruikt GPU-versnelling reeds voor zijn AI- en data analytics-oplossingen, IBM heeft de technologie omarmd voor zijn machine learning tools voor enterprises, en Oracle voegde ondersteuning toe aan zijn cloudinfrastructuur.
Ook bedrijven als Cisco, Dell EMC, Lenovo en Pure Storage hebben reeds plannen aangekondigd om Rapids in de nabije toekomst in hun systemen te integreren.