
Opensource AI-bedrijf Stability AI heeft het platform Stable Audio voorgesteld, een model dat audio genereert uit tekstprompts.
Het Britse bedrijf Stability AI heeft Stable Audio gelanceerd, een platform om tekst om te zetten naar audio. Dit is maar enkele maanden na StableStudio, een tekst-naar-beeld-platform.
Training levert op
De AI voor dit platform is getraind met meer dan 800.000 audiobestanden van muziek, geluidseffecten en voorbeelden van één enkel instrument. Samen vormen die bestanden een dataset van ruim 19.500 uren aan audio.
Daarbovenop kwam ook nog de corresponderende tekstuele metadata. Dit alles kwam tot stand via een deal met een provider voor stockmuziek, AudioSparx.
Stability AI neemt dus geen risico meer wat betreft de herkomst van trainingsdata. Er loopt nog steeds een zaak die is aangespannen door Getty Images rond beelden die zijn gebruikt om Stable Diffusion te trainen.
lees ook
Zin om een eigen ChatGPT te bouwen? Ga aan de slag met StableLM
Netwerken is belangrijk
Stable Audio maakt gebruik van latente diffusiemodellen die uit enkele componenten bestaan, vergelijkbaar met Stable Diffusion. Die delen zijn:
- Een variabele autoencoder of VAE
- Een CLAP-tekstencoder
- Een geconditioneerd diffusiemodel, gebaseerd op U-Net
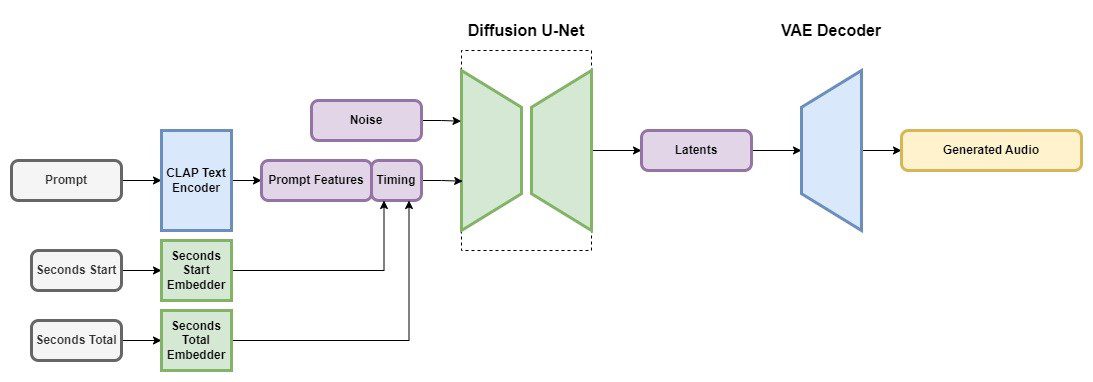
Om de AI te trainen met de tekstprompts gebruikt Stability AI een CLAP-model, omdat de tekst via dat systeem informatie kan bevatten over de link tussen woorden en geluiden. Via die tekstencoder wordt er een teksttoken naar het diffusiemodel gestuurd.
Voor de timing van de audio houdt de training rekening met twee cijfers: het beginmoment wanneer een stukje van een audiofragment wordt gebruikt en de totale duur ervan. Als een trainingsfragment bijvoorbeeld zestig seconden duurt, maar voor de training is er maar de laatste veertig seconden gebruikt, dan is die eerste waarde 20 (seconden) en die tweede waarde 60. Met deze vorm van training kan Stability AI audiofragmenten van een specifieke lengte genereren.
Het platform kan momenteel stereoclips produceren van 95 seconden lang, tegen een sample-rate van 44.1 kHz (samples zijn het audio-equivalent van pixels bij beelden). Dit gaat binnen de seconde, met een Nvidia A100 GPU.