
Na lang wachten introduceert Nvidia zijn nieuwe Ampere-architectuur voor gpu’s. De focus voor Ampere ligt op acceleratie in datacenters en de eerste Ampere-gpu, de A100, is dan ook op die markt gericht.
Nvidia zet één van zijn grootste generationele sprongen met de introductie van de Ampere-architectuur en de A100-gpu op zijn digitale GTC 2020-conferentie. Ampere volgt Volta op als datacenter-gerichte architectuur en doet zijn voorganger meteen op een reliek uit het stenen tijdperk lijken.
De Nvidia A100, speciaal gericht op AI-acceleratie, is zes keer sneller bij trainingstaken en zeven keer efficiënter in inferentie (eerder getrainde modellen uitvoeren) vergeleken met de Tesla V100. De gpu zelf heeft 54 miljard transistors aan boord verspreid over 826 mm² en is zo ’s werelds grootste 7 nm-chip. TSMC is de bakker van dienst. De Nvidia A100 bouwt voort op Volta (Tesla V100), maar steunt tegelijk ook op innovaties uit de Turing-architectuur die meer consument-georiënteerd is.
Nvidia herhaalt de aanpak van de introductie van Volta in 2017. Ook toen lanceerde de gpu-specialist zijn splinternieuwe architectuur met een volledige focus op het datacenter. Nvidia is bij veel mensen nog vooral gekend als bouwer van GeForce en Quadro-gpu’s en dat aspect van de business is nog steeds goed voor het leeuwendeel van de omzet van het bedrijf vandaag. In de toekomst rekent Nvidia erop dat het zal dalen, waardoor het vol inzet op datacenters met de bouw van acceleratoren en sinds kort zelfs een eigen netwerktak. Bij de lancering van Ampere en de A100 is er met andere woorden geen sprake van gaming- of workstationkaarten.
A100-Specificaties
De A100 is opgebouwd uit acht gpu processing clusters die elk acht texture processing clusters aan boord hebben. Elk van die clusters is dan weer voorzien van twee streaming multiprocessors (SM’s), goed voor 16 SM’s per cluster en dus 128 SM’s per gpu. Zo komen we uiteindelijk bij de kleinste en gekendste bouwstenen van de kaart: de Cuda en Tensor cores. Iedere SM heeft 64 FP32 Cuda-kernen aan boord, bijgestaan door vier Tensor cores. Voor wie geen rekenmachine bij de hand heeft: dat zijn 6912 Cuda-kernen en 432 Tensor-kernen per A100-gpu. Ter vergelijking: de ‘oude’ Tesla V100 heeft 5.120 Cuda-kernen aan boord.
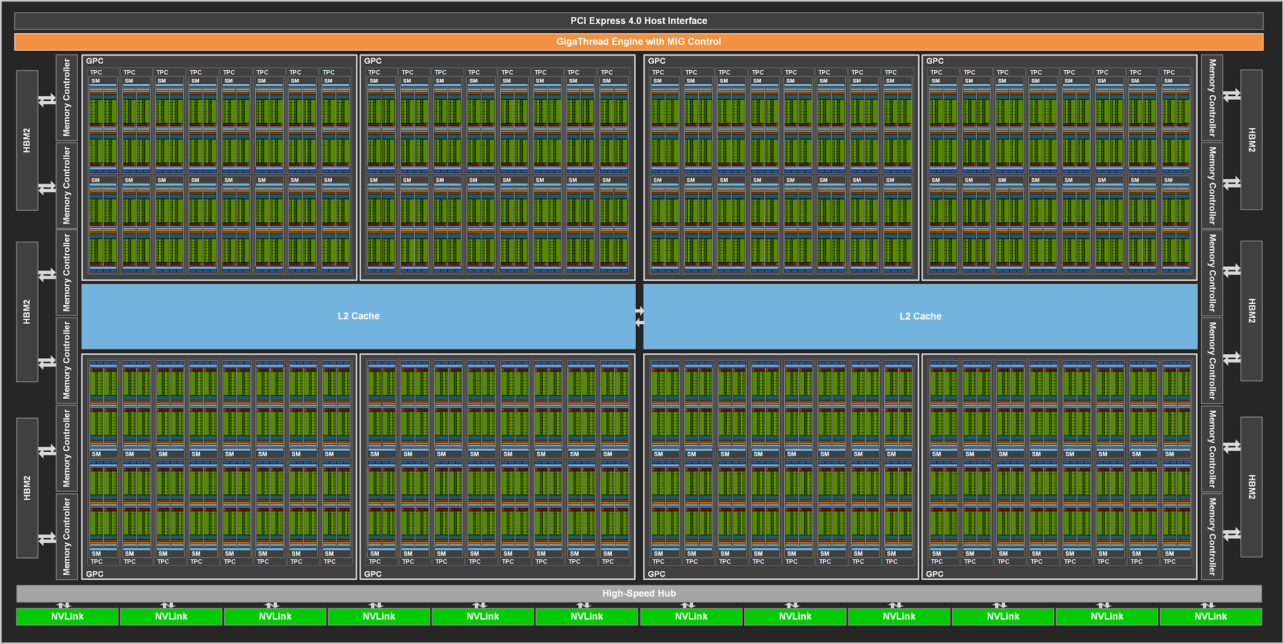
Om het monster te voeden, is er geheugen nodig. De Nvidia A100 krijgt 40 GB aan snel ECC HBM2-geheugen mee, goed voor een bandbreedte van meer dan 1,5 GB/s. Dat is maar liefst 73 procent meer dan de Tesla V100. Ook het geheugen op de chip zelf gaat erop vooruit. De L2-cache is met 40 MB zeven keer groter dan op de V100. Verder krijgt de L1 cache een boost, met 192 KB per streaming processer op de chip vergeleken met 128 KB bij de voorganger.
MIG
Omdat de nieuwe gpu zo krachtig is, introduceert Nvidia multi-instance gpu-technologie, of MIG voor de vrienden. MIG maakt het mogelijk om een enkele A100 te partitioneren in maximale zeven kleinere onafhankelijk functionerende gpu’s met hun eigen systeembronnen. Dat is met name handig in datacenters, waar A100-chips een veel flexibeler aanbod naar de eindklant mogelijk maken.
Vergelijk de opdeling met wat al lang mogelijk is bij een multicore-cpu. Een cloudprovider kan een enkele krachtige server met een 64 core-chip onder de motorkap gebruiken om verschillende klanten te voorzien van instances met bijvoorbeeld 8, 16 of 32 cores. Zo hoeft een provider niet te investeren in lichtere hardware voor consumenten die minder pk’s nodig hebben, en gaat er bovendien minder kostbare rackruimte verloren.
MIG: één server met een krachtige A100 kan dienst doen als zeven virtuele servers met minder krachtige virtuele gpu’s.
Eén server met een krachtige Nvidia A100 kan dienst doen als zeven virtuele servers met minder krachtige virtuele gpu’s voor klanten die tevreden zijn met minder rekenkracht. Omdat dat betekent dat verschillende klanten op eenzelfde chip werken, voorziet Nvidia naar analogie met cpu’s een robuuste isolatie van de partities. Het omgekeerde is ook mogelijk. Verschillende A100’s kunnen zich Voltrongewijs combineren tot een enkele nog krachtigere gpu, zoals in de DGX A100.
Nieuwe datatypes en PCIe 4.0
Ampere en de Nvidia A100 ondersteunen de nieuwe TensorFloat 32 (TF32) en Bfloat 16 (BF16) rekenformaten. Die datatypes hebben betrekking op de invoer, de manier van rekenen en de snelheid waarmee algoritmes resultaten bereiken en conclusies kunnen trekken. Zonder te veel in detail te gaan zorgt de vernieuwing ervoor dat specifieke workloads met factor 20 versneld worden vergeleken met de Tesla V100. De chip bevat bovendien nieuwe IEEE-compliant FP64-capaciteiten die de FP64-verwerking met 2,5 keer versnellen vergeleken met de V100.
De vernieuwing zorgt ervoor dat specifieke workloads met factor 20 versneld worden.
De rekenprestaties van de chip is vanzelfsprekend afhankelijk van de gebruikte datatypes. FP32 blijft desalniettemin een standaard om rekenkracht te vergelijken, en daarvoor communiceert Nvidia 19,5 teraflops.
Nvidia’s datacenter-gpu maakt gebruik van de dubbele bandbreedte die PCIe 4.0 biedt tegenover PCIe 3.1. Dat betekent dat de kaart kan genieten van een datatransfersnelheid van 31,5 GB per seconde via de interface in combinatie met compatibele processors. In de praktijk moet je daarvoor voorlopig aankloppen bij AMD’s nieuwste Epyc-processors. Nvidia combineert verschillende A100-gpu’s in een nieuw compact DGX A100-HPC-systeem en kiest onder andere om die reden voor AMD-processors in die configuratie.
Architectuur voor de toekomst
De Nvidia A100 is een beest, maar dat is niet de belangrijkste verdienste van de chip en de bijhorende nieuwe architectuur. De nieuwe hardware laat vooral zien hoe de toekomst van compute er zal uitzien. De cpu is een relatief volwassen stuk hardware dat erg flexibel wordt ingezet in datacenters, terwijl de gpu vooralsnog een nodige maar dure en al bij al onflexibele accelerator is. De architectuur van één kaart per gebruiker slaat nergens op wanneer je naar de rest van het moderne datacenter kijkt. Virtualisatie van steeds meer geconvergeerde hardware is de norm. Klanten maken gebruik van virtuele servers, vrijwel op maat samengesteld uit grotere verzamelingen van compute, geheugen en opslag.
MIG is daarom misschien wel de belangrijkste vernieuwing die Ampere met zich meebrengt. De functionaliteit maakt het immers mogelijk om gpu’s op dezelfde manier te gaan behandelen en dat brengt schaalvoordelen en kostenbesparingen met zich mee. Wat de impact op de lange termijn zal zijn, blijft afwachten, maar ga er maar vanuit dat gpu-acceleratie nog meer gemeengoed wordt dan nu al het geval is.