
Wat hebben pastinaken, unsupervised learning en aardperen gemeen? Alle drie vergeten, maar steeds een vaste waarde wanneer ze van de vergeetput in de kookpot van de data scientist belanden. Hoog tijd dus voor een herwaardering van een aantal analytics technieken.
Het is hartverwarmend, die aandacht voor vergeten groenten. Een hele generatie herontdekt de smaak van de aardpeer, pastinaak en andere posteleinen. Echt iets om toe te juichen, dankbaar dat deze vaste waarden van de vergeetput terug in de kookpot belanden. Dit geldt ook voor deze vaak vergeten technieken, ontglipt bij de nieuwe generaties data scientists en andere analytics professionals. Toch hebben ze nog steeds hun verdiensten in het huidige aanbod van bestaande oplossingen.
Lees hieronder een enthousiast pleidooi voor enkele technieken tussen alle machine, deep en andere learnings:
1. Pre-processing: Log transformatie
In een meerderheid van de algoritmes en statistische modellen vertrekken we van een ‘klokvormige’ of normale distributie, waarbij de middelste waarden ook het hoogst aantal resultaten optekenen. Denk maar aan de antwoorden op de vraag: ‘hoe groot ben je?’. Als die aan duizenden mensen wordt gesteld, krijg je gegarandeerd een grafiek in deze vorm.
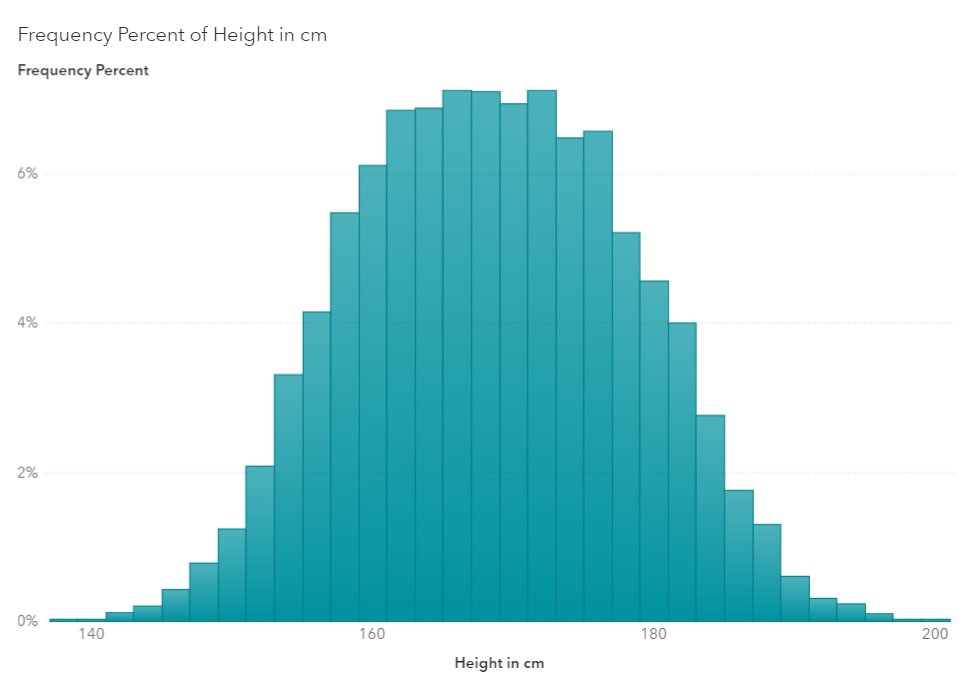
Voor sommige vragen kan je echter een totaal ander type grafiek verwachten: een linksglooiende – bij vragen als ‘hoeveel exemplaren van dit boek werden verkocht?’, waar je typisch een long tail-achtige grafiek kan verwachten – of een rechtsglooiende – bij vragen als ‘hoeveel mensen sterven er op welke leeftijd?’ – grafiek bijvoorbeeld.
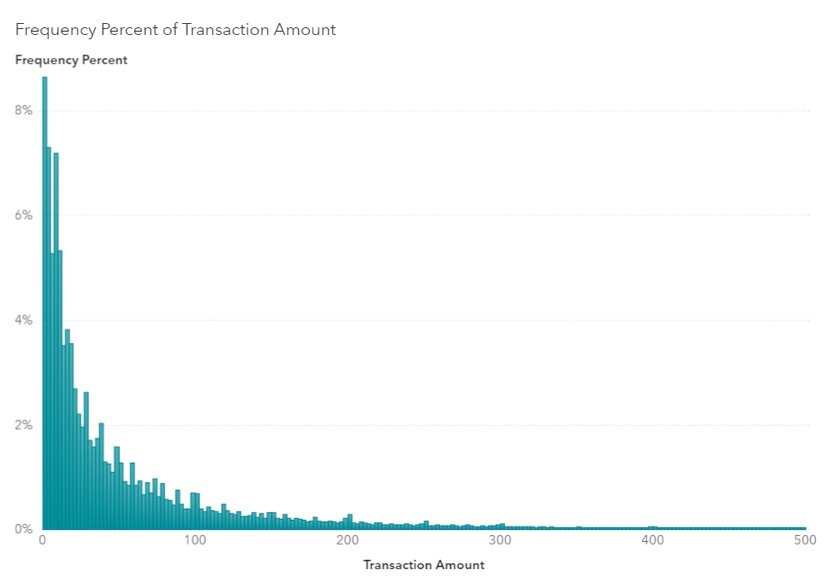
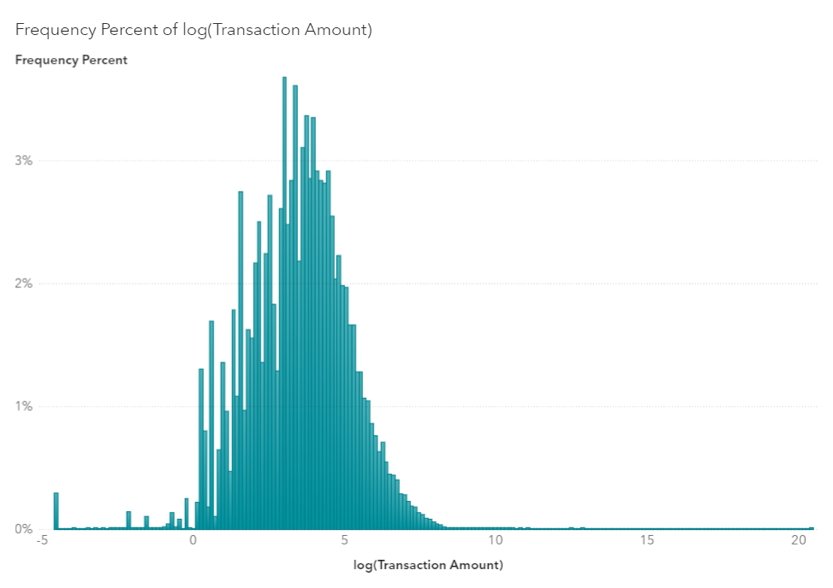
Als machine learning of andere algoritmes uitgaan van de typische klokvormige distributie kunnen ze bij die andere verdeling grondig in de fout gaan. Om de gegevens toch gebruiksklaar te maken voor verwerking, kan men dan gebruik maken van een log transformatie. Die zorgt ervoor dat een long tail of andere afwijkende distributie wordt ingepast in een courant model.
‘The curse of dimensionality’ bestrijden met PCA
Hoe meer variabelen in een model worden geïntroduceerd, hoe moeilijker het wordt om relevante informatie te distilleren uit dit model. Met een eenvoudig voorbeeld: als je tien observaties doet op een gegevensset van tien data op één as, dan is de statistische relevantie 100%. Doe je diezelfde observatie op twee assen met 10 data, dan krijg je al 100 data en wordt die relevantie herleid tot 10%. Als je weet dat vele modellen vaak uit honderden dimensies of meer bestaan, begrijp je dat je al bijzonder veel data nodig hebt om ook maar iets van statistische relevantie te bereiken. Bovendien neemt de verwerkingstijd ook exponentieel toe.
En dan hebben we het nog niet gehad over die andere ‘vloek van de dimensionaliteit’: per dimensie die wordt toegevoegd, zet je niet alleen een stap weg van bruikbare algemene conclusies, je zet ook een stap dichter bij wat de GDPR zo hardnekkig wil vermijden: persoonlijke identificeerbaarheid. Als je ‘alle vrouwen tewerkgesteld in Tervuren’ gebruikt als groep, kan dit nog op duizenden personen slaan; als je ‘alle vrouwen tewerkgesteld in Tervuren, woonachtig in Gent, met een doctoraat in filosofie, business en economie en actief als Customer Advisor Decision Science’ gebruikt, is de kans vrij groot dat je bij mij persoonlijk uitkomt.
En dan hebben we het nog niet gehad over die andere ‘vloek van de dimensionaliteit
Een deel van deze vloek kan je opheffen door een eenvoudige ingreep, die grofweg neerkomt op het combineren van twee of meer variabelen tot één zinvolle variabele. Zinvol betekent dat je op die manier data groepeert die anders over twee assen verspreid zouden staan en die nu een betekenisvolle groep vormen. Als je data over geldafnames van een bankautomaat spreidt over diverse assen zoals plaats, tijd van afname en bedrag, is de kans reëel dat hier weinig zinvolle interpretaties uit volgen. Als je bijvoorbeeld een gecombineerde variabele ‘bedrag op tijd van de dag’ introduceert, wordt de kans op een bruikbaar inzicht plots veel groter. Deze ingreep noemen we in het vakjargon ‘principal component analysis’ en blijft een belangrijke sleutel tot het succes van machine learning modellen.
2. Modelleren: Unsupervised learning
Misschien wel de oudste van alle hier besproken technieken is ‘unsupervised learning’. Het lijkt gloednieuw, want het zit vaak verweven in de huidige machine learning modellen, en toch dateert het concept al van de vroege eighties. Toen werd het meestal ‘self-organizing maps’ genoemd.
In feite werkt deze techniek zoals ons menselijk brein: je gaat data die dicht bij elkaar liggen groeperen in een soort zelf-organiserende groep op basis van nabijheid en vergelijkbaar gedrag. Net zoals bij je brein geef je het model de kans om zelf verbanden te ontdekken en clusters te bouwen zonder dat die vooraf worden opgelegd. Het mag duidelijk zijn dat dergelijke technologie de basis vormt voor deep learning en andere geavanceerde modellen. Vergelijk het gerust met een vergeten groente als basisingrediëntje voor een topgerechtje in een of ander sterrenrestaurant.
3. Post-processing: Geleidelijke logistische regressie
Wie na het modelleren met een overdreven aantal variabelen overblijft, heeft twee keuzes: ofwel vertrek je vanuit nul variabelen en ga je gaandeweg variabelen toevoegen die de meest significante resultaten opleveren, ofwel start je vanuit alle variabelen en neem je gaandeweg variabelen weg waarvan je merkt dat hun afwezigheid weinig tot geen invloed heeft op de bereikte resultaten.
Wie na het modelleren met een overdreven aantal variabelen overblijft, heeft twee keuzes
Vooral de tweede aanpak kan zorgen voor een gevoelige vereenvoudiging van de modellen zonder het risico te lopen dat je significante variabelen uit het oog verliest.
Segmentatie
Segmentatie is een basisbegrip in elke cursus analytics, en toch wordt dit vaak uit het oog verloren in de post-processing fase. Eigenlijk doe je niet minder of meer dan een extra controle op mogelijke ‘bias’, op vooroordelen die onbewust in je modellen zijn geslopen. De techniek is even eenvoudig als belangrijk: je algemene resultaten deel je op in specifieke segmenten, en zo ga je na of de voorspellingen uit het model ook kloppen voor de verschillende subsegmenten.
Stel (fictief voorbeeld) dat jouw model voorspelt dat 95% van de vrouwen en slechts 65% van de mannen tijdig en volledig een genomen lening terugbetaalt. Dan doe je er goed aan om na te gaan of dit in de praktijk ook het geval is. Is dat zo, dan heb je een goed werkend model opgesteld. Zijn de verschillen veel minder groot, dan is je model misschien aan herziening toe. Diezelfde oefening kan je ook nog op andere subsegmenten toepassen: autochtoon vs allochtoon, jong vs oud, werknemer vs zelfstandige enz.
Post-processing segmentatie kan het verschil maken tussen een goed model en een uitstekend model.
Post-processing segmentatie lijkt misschien voor de hand liggend en allesbehalve sexy, maar het kan wel het verschil maken tussen een goed model en een uitstekend model. En dus ook tussen een matige en een enorme impact op het bedrijfsresultaat. Net zoals de vergeten groenten kan deze vaak vergeten techniek, en de andere vier die we hierboven hebben besproken, de moeite van het herontdekken en herwaarderen meer dan waard blijken.
Dit is een ingezonden gastbijdrage van Véronique Van Vlasselaer, Customer Advisor Decision Science bij SAS België & Luxemburg. Via deze link vind je meer informatie over de oplossingen van het bedrijf.