
Fan van ChatGPT maar wil je liever geen gegevens richting OpenAI sturen? Ga met de lokale versie van ChatGPT aan de slag. We leggen je uit hoe je ermee start.
ChatGPT bevat achterliggend een LLM, kort voor Large Language Model. Die draait op de servers van OpenAI waar heel wat rekenkracht ervoor zorgt dat je direct een antwoord op je vraag krijgt. Het nadeel daarvan is dat je een clouddienst gebruikt. Je vragen (en antwoorden) zijn niet privé. Gevoelige bedrijfsdata doorsturen om conclusies te vormen doe je beter niet.
Om toch ChatGPT te gebruiken, kan je sinds kort een downloadbare versie gebruiken die openbron is. Snel downloaden en gebruiken? Helaas is het niet zo gemakkelijk. Een LLM lokaal gebruiken, vereist specifieke tools.
Voor deze how-to maken we gebruik van Ollama, een van de meest gebruiksvriendelijke opties op de markt. De screenshots die je hier ziet komen van een Windows-pc, maar de stappen zijn identiek voor Mac.
-
Stap 1: De sterkte van je GPU bepalen
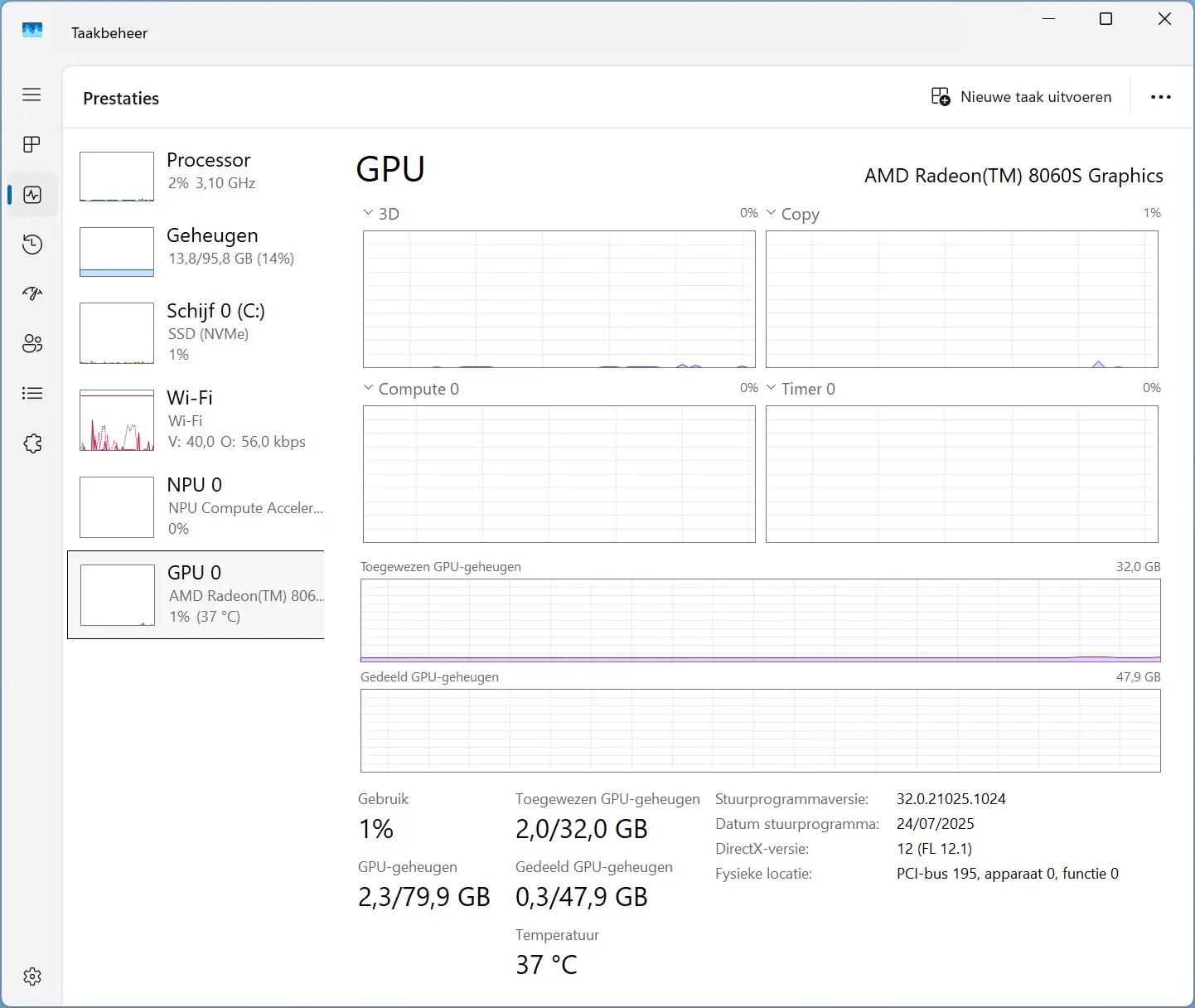
 Voor je direct enthousiast modellen gaat testen, moet je eerst weten of je pc compatibel is. Een LLM lokaal draaien, vraag heel veel rekenkracht en VRAM. Dat laatste is de hoeveelheid geheugen van je grafische kaart (GPU). Druk tegelijk Ctrl+Shift+Esc in op een Windows-pc en kies links GPU. Onder GPU-geheugen centraal onderaan zie je hoeveel je GPU nu verbruikt van zijn geheugen en hoeveel het in totaal beschikbaar heeft.
Voor je direct enthousiast modellen gaat testen, moet je eerst weten of je pc compatibel is. Een LLM lokaal draaien, vraag heel veel rekenkracht en VRAM. Dat laatste is de hoeveelheid geheugen van je grafische kaart (GPU). Druk tegelijk Ctrl+Shift+Esc in op een Windows-pc en kies links GPU. Onder GPU-geheugen centraal onderaan zie je hoeveel je GPU nu verbruikt van zijn geheugen en hoeveel het in totaal beschikbaar heeft. -
Stap 2: Welke modellen kan je draaien?
Hoe hoger het GPU-geheugen, hoe beter. 16 GB heb je vandaag minimaal nodig om de basismodellen vlot te draaien. Een volledig overzicht van alle LLM’s die met deze how-to compatibel zijn, vind je hier.
Elk model heeft verschillende varianten, elks met een aantal miljard parameters. Kleine modellen herken je aan de 1b of 0,6b of 4b: respectievelijk 1, 0,6 en 4 miljard parameters. Die kan je vlot draaien met een GPU met 16 GB geheugen.
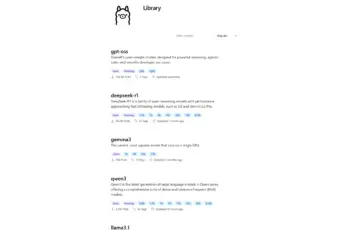 Hoe meer parameters, hoe beter het resultaat. De opensource-versie van ChatGPT die je lokaal kan draaien, heeft respectievelijk 20 en 120 miljard parameters aan boord en dragen de labels 20b en 120b.
Hoe meer parameters, hoe beter het resultaat. De opensource-versie van ChatGPT die je lokaal kan draaien, heeft respectievelijk 20 en 120 miljard parameters aan boord en dragen de labels 20b en 120b.OpenAI laat weten dat de 20b-versie van ChatGPT minimaal 16 GB vereist. De 120b-versie heeft een GPU met 80 GB nodig. Dat laatste is behoorlijk exotisch en vind je enkel in Apple M-chips, Nvidia H100 GPU’s of een AMD Ryzen AI Max+ APU.
Een handige vuistregel: het aantal parameters in miljard komt ongeveer overeen met de hoeveelheid geheugen dat je GPU nodig heeft om te presteren. Heb je maar weinig GPU-geheugen? Experimenteer met kleine modellen. Wil je ChatGPT lokaal draaien? Dan heb je minimaal 16 GB nodig.
-
Stap 3: Ollama installeren
Download voor je start de juiste versie via deze link: Windows, Linux of macOS. Wij gaan in deze gids verder met de Windows-versie. Klik op de knop Download for Windows. Het installatiebestand is bijzonder eenvoudig: klik op Installeren. Hiermee ben je klaar om LLM’s te testen op je pc.
-
Stap 4: Taalmodellen downloaden
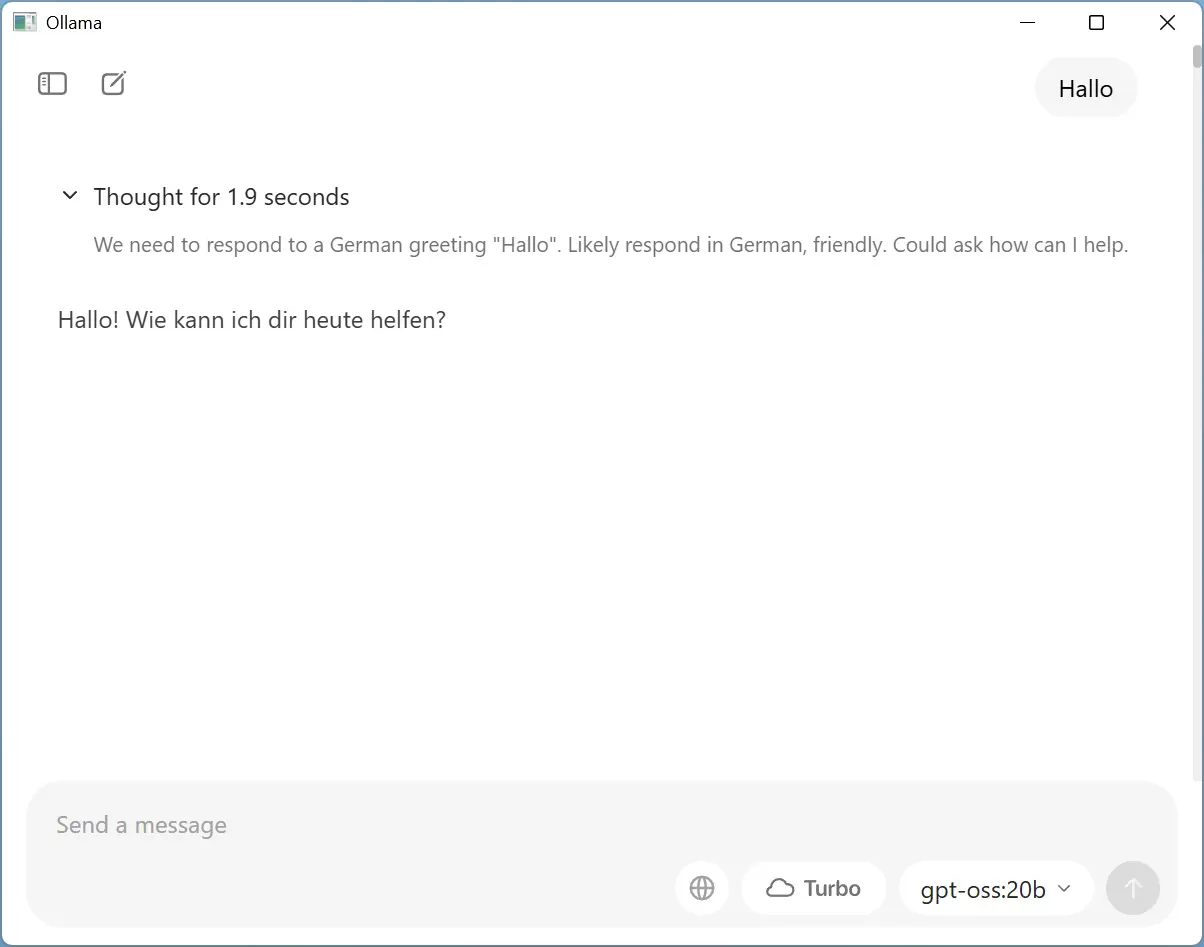
Voor we ChatGPT kunnen gebruiken, moeten de LLM eerst lokaal zetten. Start Ollama en kies rechts gpt-oss:20b. Typ Hallo in het berichtvenster om de download te starten. Op het moment van schrijven is het model 12,8 GB groot. Wanneer de download klaar is, zal ChatGPT een antwoord formuleren.
Je kan hetzelfde herhalen voor andere modellen in het menu. De grafische interface van Ollama ondersteunt vandaag ChatGPT, Deepseek, Gemma en Qwen. Andere modellen kan je aanroepen via de Windows Terminal, maar dat gaan we hier niet bekijken in deze how-to. We focussen nu op ChatGPT en de gebruiksvriendelijke interface van Ollama die daarvoor werd gebouwd.

-
Stap 5: Lang wachten op antwoorden?
Een LLM is zoals de naam het zegt een groot taalmodel met miljarden parameters. Afhankelijk van hoe krachtig je GPU is en hoe veel geheugen het heeft, kan een antwoord lang op zich laten wachten. Ook de complexiteit van je vraag heeft een impact. De taal maakt niet uit: Frans, Nederlands, Engels, het model ondersteunt heel veel talen.
Je kan in Ollama vragen of het je kan helpen met een samenvatting van een project. Het antwoord daarop zal redelijk snel volgen. Wanneer je de samenvatting doorstuurt, dan begint het echte werk pas en kan het soms tot een half uur duren voor het antwoord er is.
Ollama en de lokale versie van ChatGPT heeft ook zijn beperkingen. Je kan geen bestanden uploaden om te analyseren of beelden laten genereren. Daarvoor kan je enkel terecht bij de online versie van ChatGPT.


Moet je soms minuten wachten op een antwoord? Nu weet je pas hoe krachtig ChatGPT in de cloud is met miljoenen GPU’s die klaarstaan voor jou. Door een model lokaal te draaien, krijg je vat op de rekenkracht die vereist is om taalmodellen. En de energie die daarvoor nodig is om de GPU’s aan te sturen (en af te koelen). Gebruik daarom de online versie van ChatGPT nuttig.
Leuk detail: het lokale model van ChatGPT geeft ook zijn redenering aan. Zo kan je letterlijk volgen hoe het een vraag wil aanpakken en soms een kritische noot toevoegt wanneer je doorvraagt op details of feiten.
Ondertussen maakt OpenAI zich op voor de lancering van GPT-5. GitHub lekte al de eerste gegevens uit.