Edge computing is een term die je steeds vaker hoort vallen op belangrijke technologieconferenties. De technologie gaat hand in hand met het Internet of Things en betekent in zekere zin een stap terug van de cloud. Nu we drie buzzwoorden in één inleiding hebben verwerkt, is het tijd voor wat duiding.
Eenvoudig gesteld betekent edge computing dat een deel van de dataverwerking dichter bij de bron van de gegevens wordt uitgevoerd, in plaats van ze eerst halfweg over de aarde te sturen naar een datacenter voor verwerking in de cloud. Dat leidt tot kostenbesparing, minder bandbreedteverbruik, verbeterde veiligheid en een lagere latency.
Gedistribueerd model
Peter Levine, partner bij investeringsmaatschappij Andreessen Horowitz, maakte enkele jaren geleden de analyse dat de geschiedenis van de computerindustrie wordt gekenmerkt door periodieke wissels tussen gecentraliseerd en gedistribueerd computergebruik.
Het begon allemaal met de mainframe, een centrale computer waar sinds de jaren 70 ‘domme’ terminals op werden aangesloten om instructies door te geven. Vanaf de jaren 80 verhuisde een deel van de rekenkracht naar de personal computer en evolueerden we naar een gedistribueerd client-servermodel. In de jaren nul keerden we volgens Levine terug naar een gecentraliseerd model met mobile en cloud als drijvende krachten. Het rekenwerk werd opnieuw gecentraliseerd, met onze smartphone als ‘terminal’.
Met edge computing slaat de slinger weer door in de andere richting, en evolueren we opnieuw naar een gedistribueerd model.
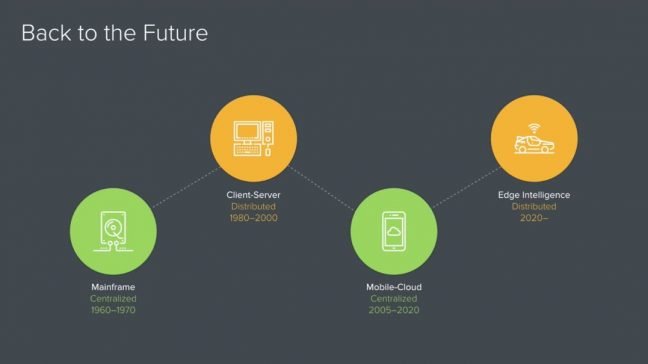
Beeld: Peter Levine
Wildgroei aan data
Aan de basis van die trend ligt de opkomst van slimme apparaten en sensoren, die een wildgroei aan data produceren. GSMA, de wereldwijde belangenvereniging voor mobiele operatoren, voorspelt dat het totale aantal IoT-verbindingen tegen 2025 zal stijgen tot 25,2 miljard. In 2016 werden nog maar 6,3 miljard geconnecteerde apparaten geteld.
Meer dan de helft van die verbindingen (13,8 miljard) zullen zich in zakelijke en industriële omgevingen situeren, voor de optimalisatie van bedrijfsprocessen. Het simpelweg verbinden van apparaten, is dan niet voldoende. De gigantische hoeveelheden data die zo worden gegenereerd, zijn op zichzelf waardeloos.
“Het gaat om wat je met de data doet”, weet ook Michael Garcia, Senior Technical Program Manager bij AWS IoT. “Het zijn de bedrijfsresultaten die belangrijk zijn. IoT is maar een hulpmiddel.”
Om betere bedrijfsresultaten te behalen met behulp van IoT, moet de data van sensoren en slimme apparaten worden geanalyseerd om inzichten uit te halen. Dat gebeurt vandaag vooral in de cloud, ofwel centraal in het datacenter, maar vindt ook steeds meer plaats in de edge, aan de rand van het netwerk.
Edge computing
Bij edge computing worden gegevens in eerste instantie lokaal opgeslagen en verwerkt, zo dicht mogelijk bij de bron van de data. Dat kan op het IoT-apparaat zelf zijn, als het over voldoende rekenkracht en opslagcapaciteit beschikt, of in een ‘mini-datacenter’ dat de informatie van meerdere nabije IoT-apparaten verzamelt en analyseert.
Beeld: AWS Greengrass
Garcia onderscheidt drie redenen waarom je de voorkeur zou geven aan edge computing in plaats van cloud computing.
De eerste reden is economisch. Soms is het simpelweg te duur om alle data naar de cloud te sturen, weet de IoT-expert. Hij haalt daarbij het voorbeeld aan van Nokia, dat gebruik maakt van AWS Greengrass om de analyse van videobeelden van slimme camera’s in de stad lokaal uit te voeren. “Als je alle informatie van die camera’s voortdurend in een hoge resolutie naar de cloud stuurt, zal dat heel wat geld kosten. Soms is het zelfs onmogelijk. Op de schaal van een stad heb je bijzonder veel bandbreedte nodig”, vertelt Garcia. “Met behulp van lokale beeldherkenning, kunnen de camera’s afwijkingen in het verkeer detecteren – bijvoorbeeld een botsing van twee wagens – en pas dan zelf beslissen om de beelden naar de cloud te sturen voor centrale verwerking.”
Een tweede voordeel heeft betrekking tot regulering en wetgeving. Garcia: “Als je de gegevens moet anonimiseren of op een andere manier bewerken voor je ze naar de cloud stuurt, kan dat eerst lokaal gebeuren.” Denk bijvoorbeeld aan een ziekenhuis dat medische gegevens van patiënten wil gebruiken om machine-learningmodellen voor het herkennen of voorspellen van ziektebeelden te trainen in de cloud.
“De cloud is het brein, de edge is het zenuwstelstel dat taken heel snel uitvoert”
“De laatste reden is dat we nog altijd geen goede oplossing hebben om sneller te gaan dan het licht”, lacht Garcia. “Als de data eerst naar de cloud en terug moeten reizen voordat een actie kan worden genomen, zit er enige vertraging op de analyse.” Dat gaat misschien om een seconde of minder, maar is voldoende om in sommige situaties – waar beslissingen in realtime moeten worden gemaakt – nog te veel te zijn. Zelfrijdende auto’s zijn in dit geval een goed voorbeeld, maar ook bijvoorbeeld automatische robotarmen in de productielijn hebben er baat bij om de latency zo laag mogelijk te krijgen.
Brein en zenuwen
Hoewel de edge in de (nabije) toekomst ongetwijfeld alleen maar verder aan belang zal winnen, betekent het niet dat cloud ten dode is opgeschreven.
“We zien steeds meer interesse bij klanten om naar de edge te verschuiven.”, vertelt Garcia. “Soms is het gewoon logisch om zaken lokaal uit te voeren, dus doen we dat meer. En soms is het logischer om in de cloud te werken, vooral wanneer je veel rekenkracht nodig hebt.”
Bij machine learning blijft de cloud voorlopig onmisbaar. Machine-learningmodellen kunnen in de edge worden toegepast op de verzamelde data, maar om de modellen te verbeteren en verder te trainen is de brute kracht van de cloud nodig.
Een andere reden waarom de cloud volgens Garcia onontbeerlijk blijft, is het centrale beheer van apparaten en diensten voor onder meer de uitrol van (firmware-)updates of probleemoplossing op afstand.
“De cloud is het brein, de edge is het zenuwstelstel dat taken heel snel uitvoert, soms zelfs zonder naar het brein terug te koppelen.”, besluit de IoT-expert.