Nu het steeds moeilijker wordt om de transistordichtheid op chips te vergroten, komt de grootste prestatiewinst in computerland van zogenaamde accelerators. De chips op maat bieden nu grote prestatiewinsten, maar die zijn niet structureel.
Zowel aan de hoge kant van het spectrum, in HPC-land, als aan de onderkant bij de smartphones, wordt het alsmaar moeilijker om snellere en zuinigere chips te maken. De wetten van de natuurkunde beginnen roet in het eten te strooien. Het wordt uitdagender om kleinere transistors te bouwen, waardoor veel prestatiewinst vandaag uit een andere hoek komt. Chips worden gespecialiseerder ontworpen op maat van specifieke workloads. Dergelijke gespecialiseerde chips, ook wel accelerators genoemd, werken in tandem met generalistische gpu’s voor hogere prestaties.
Sprong vooruit
Dat werkt vrij goed. Denk aan de sprongen voorwaarts in AI en deep learning met dank aan gpu-accelerators, maar ook aan gespecialiseerde chips voor bijvoorbeeld fotografie of beeldherkenning in je smartphone. Of FPGA’s in datacenters, die door klanten op maat van een workload geprogrammeerd worden.
De versnelling die accelerators met zich meebrengen is belangrijk, maar niet structureel.
De verschuiving naar doelgerichte chips op maat van specifieke workloads lijkt de vertraging in de vooruitgang op het vlak van chipfabricage vlot te mitigeren. Onderzoek wijst echter uit dat de versnelling die accelerators met zich meebrengen belangrijk, maar niet structureel is. Eens de accelerator-joker is uitgespeeld, valt chipdesign terug naar zijn steeds tragere ontwikkelingscadans.
CMOS versus architectuur
Onderzoekers van de Amerikaanse Universiteit van Princeton hebben geprobeerd om in kaart te brengen wat de relatie is van innovatie op het vlak van schaalverkleining versus innovatie gericht op architectuur en specialisatie, waaronder accelerators vallen. Een accelerator, hoe specifiek ook, wordt immers gebouwd met precies dezelfde CMOS-technologie als alle andere microchips. Hun onderzoek richt zich op de impact op de lange termijn.
De researchers brachten prestatiedata van duizenden echte chips in kaart en bouwden daarmee een model. Het doel was om een onderscheid te maken tussen prestatiewinst afkomstig van CMOS-technologie en prestatiewinst met een andere oorsprong. De conclusie was voor ieder type gespecialiseerde chip: vroeg of laat lopen chipbouwers tegen een ‘accelerator wall’ aan.
Het belang van formaat
Om te begrijpen waarom, frissen we nog eens op wat het belang van nodeverkleining in CMOS-technologie is. CMOS-transistors vormen de basis van iedere moderne chip. Transistors worden via interconnects verbonden in logische schakelingen die de chip in staat stellen rekenwerk te verrichten. Hoe kleiner de transistor, hoe meer er op een chip van een gegeven formaat passen en hoe complexer de schakelingen kunnen zijn. Dat is de transistordichtheid. Kleinere transistors brengen echter twee andere, minstens even belangrijke, voordelen met zich mee.
Hoe kleiner de transistor fysiek is, hoe kleiner de afstand tussen source en drain. Concreet: er is een lager voltage nodig om de halfgeleider te switchen van 0 naar 1 en de switch gaat sneller. Dat zorgt er op zijn beurt voor dat de chip minder snel warm wordt. Een identiek chipdesign, met een identieke hoeveelheid transistors en identieke schakelingen, werkt sneller wanneer het is gebakken op een 7 nm-proces dan op een 14 nm-proces. De nanometer-terminologie heeft trouwens geen rechtstreekse betrekking op het formaat van de transistors zelf, maar is dezer dagen een ietwat arbitrair cijfer gebaseerd op verschillende factoren. Zo is 10 nm bij Intel ongeveer vergelijkbaar met 7 nm bij TSMC.
Andere chip, zelfde blokken
Een accelerator zoals een gpu, TPU, ASIC, FPGA of éénder welke andere gespecialiseerde chip, onderscheidt zich van een klassieke processor omdat hij op maat van specifiek rekenwerk werd ontwikkeld. Een klassieke gpu is bijvoorbeeld goed in het renderen van beelden, een TPU in Tensorflow-rekenwerk en een FPGA is herprogrammeerbaar om verschillende soorten workloads beter te ondersteunen. De verschillen bestaan uitsluitend op het niveau van het chipdesign: de schakelingen tussen de transistors, de interconnects, de plaatsing van geheugen… De blauwdruk is volledig anders dan die van pakweg een Intel Xeon-cpu, maar de bouwstenen zijn dezelfde.
De blauwdruk is volledig anders dan die van pakweg een Intel Xeon-cpu, maar de bouwstenen zijn dezelfde.
De onderzoekers ontdekten dat de marginale opbrengst van die unieke designs na verloop van tijd zonder fout afneemt. Wanneer er een populaire workload wordt gedefinieerd en er vervolgens een accelerator op maat wordt gebouwd, is de winst in eerste instantie natuurlijk groot. In de eerste jaren is er bovendien heel wat mogelijk in termen van architectuur. De accelerators worden verbeterd, workload en chip worden beter op elkaar afgestemd en het lijkt alsof de Wet van Moore is herrezen met een adrenaline-injectie in het hart op de koop toe.
Eenmalige boost
Op de lange termijn blijven de verbeteringen helaas nooit duren. Generatie na generatie wordt het belang van architectuur en design voor een gegeven categorie accelerator kleiner en wint het aandeel van de gebruikte node in de prestaties die mogelijk zijn. Na verloop van tijd stagneert de innovatie en blijft er één bepalende factor over: CMOS-formaat.
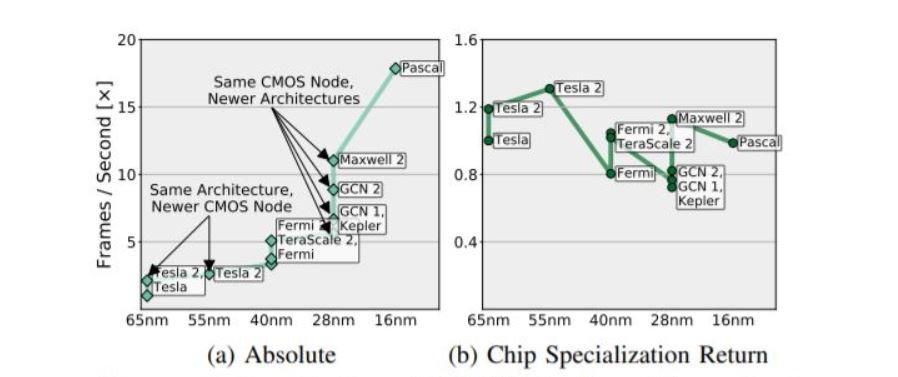
Wat we vandaag meemaken, moeten we dan ook interpreteren als een belangrijke sprong voorwaarts in beschikbare rekenkracht, die desalniettemin niet structureel is. Node-verkleining blijft de enige constante bron van innovatie, maar ze raakt uitgeput. Hoe kleiner transistors worden, hoe minder goed elektriciteit zich gedraagt binnen een chip. Kwantumeffecten beginnen roet in het eten te gooien en dat is dan maar wanneer je erin slaagt een chip effectief te bouwen.
Kleiner dan licht
Microchips bouwen, gebeurt via een gelaagd chemisch proces waarbij blauwdrukken laag na laag geprojecteerd worden op een coating. Al naargelang welk deel van de coating bestraald wordt, blijft er een stukje liggen. Het proces heet lithografie en wordt al sinds jaar en dag gebruikt om transistors en interconnects stap voor stap op te bouwen. Het probleem vandaag: de golflengte van de straling die gebruikt wordt om de blauwdrukken te projecteren is groter dan de gewenste resolutie van de blauwdrukken.
De afgelopen halve eeuw is CMOS-transistortechnologie bijna helemaal uitgepuurd.
Zichtbaar licht is al lang niet meer aan de orde. Vandaag wordt ‘deep UV’-straling gebruikt, maar ook die volstaat niet. De sprong naar Extreme UV dring zich op vanaf 7 nm en kleiner, maar die straling heeft zo’n kleine golflengte dat ze door vrijwel alles geabsorbeerd wordt, inclusief de spiegels in de lithografiemachines. De combinatie van de kwantumeffecten en de natuurkundige limieten van het lithografieproces houden in dat het op een bepaald moment onmogelijk zal worden om de bestaande technologie verder te verkleinen. De afgelopen halve eeuw is CMOS-transistortechnologie zodanig uitgepuurd, dat je bijna zou vergeten dat de basisprincipes in al die tijd niet veranderd zijn.
Totaal nieuwe concepten
Het onderzoek toont aan hoe belangrijk het is om out-of-the-box te denken. Nieuwe materialen, maar ook volledig nieuwe chipprincipes dienen onderzocht te worden, liefst met resultaat voor de accelerator wall bereikt wordt. Anders zal de rekencapaciteit van chips voor het eerst sinds de uitvinding ervan onvermijdelijk stagneren. Denk daarbij aan radicale vernieuwingen, die nog verder gaan dan bijvoorbeeld neuromorfische processors. Neuromorfische chips worden immers nog steeds in een klassieke fab gebakken, met dezelfde bouwstenen, en zijn in dat opzicht niets meer dan een nieuwe accelerator.
Hetzelfde geldt voor andere vernieuwingen, zoals memory driven computing. Daar zit heel veel potentieel en een doorbraak op dat vlak kan de evolutie van rekenkracht nog vele jaren zoet houden, maar vroeg of laat komt de accelerator wall ook daar in zicht. Intel werkt vandaag naarstig aan wat het Magneto-Electric Spin Orbit (MESO) noemt. Onderzoek zit nog in zijn kinderschoenen en het zal nog zeker een decennium duren voor MESO iets kan betekenen, maar de technologie zet in op de verhoging van de dichtheid en verlaging van switch-voltages, los van CMOS-scaling. MESO belooft met andere woorden wel een fundamentele oplossing te bieden voor de beperkingen van het schaalprobleem vandaag.
Gerelateerd: 10 nm Ice Lake in volumeproductie in twee Intel-fabrieken