
In de publieke sector krijgen administraties enorme hoeveelheden documenten te verwerken en te beheren. Deze documenten moeten worden geïndexeerd en georganiseerd, zodat informatie zo vlot mogelijk terug te vinden valt. In deze context is NER of Named Entity Recognition, een techniek gebaseerd op machine learning en Natural Language Processing (NLP), een bijzonder interessante oplossing. Ze laat toe om automatisch informatie op te halen uit documenten in tekstvorm, audio of video.
NER bestaat erin om bij naam genoemde entiteiten (Named Entities) te herkennen in een corpus (verzameling van teksten) en om er een label aan toe te kennen, bijvoorbeeld “naam”, “plaats”, “datum”, “e-mail”… Waar NER oorspronkelijk verwees naar de extractie van eigennamen, zoals de naam van een persoon, plaats of organisatie, werd het concept verbreed naar andere entiteiten – denk aan een datum, e-mailadres, geldbedrag, enzovoort. In veel gevallen wordt de technologie gebruikt om domein-specifieke termen terug te vinden, zoals bijvoorbeeld de IBAN-code voor het beheer van bankverrichtingen, of de naam van genen in de biomedische wereld.


NER werd origineel ontwikkeld voor het opsporen van informatie (information retrieval), maar heeft vandaag heel wat meer toepassingen dan enkel het indexeren van documenten. Het wordt met name gebruikt in vraag-en-antwoord-systemen (Q&A): die bestaan erin om een antwoord te bieden op een vraag gesteld in natuurlijke spreektaal, door het antwoord op te zoeken in een verzameling documenten of in een kennisbeheersysteem. Voor dit soort gebruik kan NER erg nuttig zijn, om vast te stellen welk type antwoord het Q&A-systeem moet bieden op basis van de entiteiten in de vraag (bv. een plaats, een datum…).
Ook kan NER worden gebruikt om vooraf andere taken uit te voeren zoals een semantische annotatie, een machinevertaling, een classificatie of om een ontologie te voeden.
Hoe implementeer je een NER-systeem?
Meerdere manieren zijn mogelijk om een NER-systeem te implementeren. De eerste bestaat erin om vooraf vastgelegde regels te gebruiken (vaak ‘reguliere expressies’ maar ook samengestelde regels op basis van morfosyntactische labels). Regels bieden als voordeel dat ze snel te implementeren zijn, maar hun bereik is beperkt. In het voorbeeld hieronder gebruiken we een reguliere expressie om een telefoonnummer te herkennen. We stellen vast dat, naargelang de structuur van het telefoonnummer, dit al of niet zal worden gedetecteerd door het NER-systeem. We moeten dus complexe regels gaan gebruiken om alle mogelijke situaties en varianten te voorzien. Dit is een voorbeeld van een expressie waarmee we een telefoonnummer kunnen herkennen:
“^0d{1,3}/d{2,3}.d{2,3}(.d{2})?$”

Een andere aanpak bestaat erin om ‘statistische’ methodes te gebruiken, namelijk via machine learning en recenter via deep learning. Het voordeel van deze technieken is dat we de context gaan gebruiken om een entiteit te herkennen, en om er een categorie aan toe te kennen. Als we kijken naar namen zoals Brussel of Pierre Dupont, dan kunnen we ze herkennen op basis van regels met behulp van onder meer de woordstructuur en de morfosyntactische elementen, maar het zal moeilijk zijn om alle entiteiten in de juiste categorie te stoppen. Niettemin vraagt het gebruik van machine learning / deep learning om een groot aantal manueel geannoteerde teksten voor het trainen en evalueren van het NER-model.
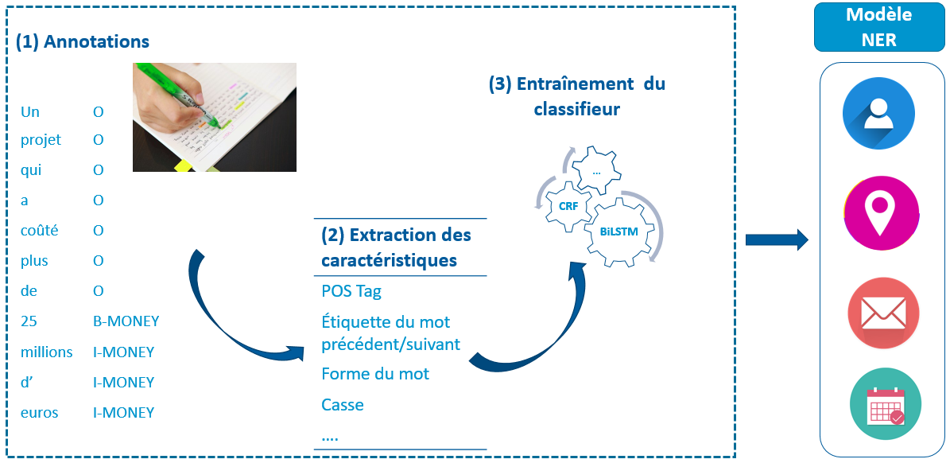
Training van een statistische NER : de eerste stap bestaat erin om de gegevens te annoteren volgens een duidelijk vastgelegd label-formaat – BIO, BIOES of BILOU – gevolgd door een extractie van de karakteristieken (POS-tag, label van voorafgaand of volgend woord, hoofd- of kleine letters, woordvorm…) die als input dienen voor het trainen van de classificatie.
In de praktijk is een efficiëntie NER-implementatie een combinatie van regels en statistische methodes. Door de hoge kost in tijd en middelen van het annoteren van gegevens en het ontwikkelen van een NER-model, kiezen we zoveel mogelijk voor formele regels voor de detectie van entiteiten.
De implementatie van een NER-systeem en in het bijzonder van een NER-systeem op basis van machine learning/deep learning houdt een aantal uitdagingen in:
- Taal : Voor het toepassen van een statistisch model, is de taal waarin het model wordt getraind bepalend. Er bestaan NLP-tools (natural language processing) die toelaten om ‘out of the box’ entiteiten te herkennen. De meeste NER-tools zijn echter hoofdzakelijk ontwikkeld voor het Engels, en weinig of geen voor het Frans en het Nederlands.
- Het type van tekst: Een model dat op een specifieke tekststructuur werd getraind, zal niet altijd werken voor andere types.
- Het type van entiteit dat je wil herkennen.
- OCR: Het digitaliseringsproces van niet-digitale documenten via optical character recognition zorgt voor fouten die een impact hebben op de performance van NER.
- Ambigue entiteiten: Gevallen van metonymie en polysemie zijn moeilijk af te handelen. Bijvoorbeeld, spreekt de zin “dat wordt allemaal in Brussel beslist”, over de stad, of over de Europese Unie?
- Weinig gegevens: Vaak zijn er erg weinig data beschikbaar om de NER te trainen. Transfer learning is een manier om met deze moeilijkheid om te gaan. Het bestaat erin om een generiek NER-model te nemen, getraind voor een domein waarvoor wel veel gegevens beschikbaar zijn, en het te verbeteren op basis van beperkte data voor het domein dat ons interesseert.
- Manuele annotatie van een corpus blijft een zware taak, hoewel er tools bestaan om dit semi-automatisch te doen.


De resultaten van NER zijn dus lang niet perfect. Daarom combineer je in een concrete implementatie best waar mogelijk NER met een validatie-stap. In het voorbeeld hierboven, heeft de NER-module het woord ‘Diables’ als een entiteit herkend en het vervolgens gecategoriseerd als een plaatsnaam (LOC). Het is vrij eenvoudig om het bestaan van zo’n entiteit te verifiëren door ze te vergelijken met een geografische databank zoals GeoNames of OpenStreetMap.
Named Entitiy Recognition is kortom een techniek voor het automatisch verwerken van natuurlijke taal (NLP), die erg nuttig is voor het automatisch verwerken van documenten. Hoewel de entiteiten voor de mens heel gemakkelijk te herkennen zijn, verloopt de automatisering van deze taak niet zonder moeilijkheden. In de praktijk is NER bruikbaar om vlotter documentaire opzoekingen te doen, om elektronische post en documenten automatisch naar de juiste diensten door te sturen, om facturen automatisch te betalen, om semantische verrijking te doen…
Dit artikel is een individuele bijdrage van Katy Fokou, gespecialiseerd in artificiële intelligentie bij Smals Research. Het is in eigen naam geschreven en neemt geen standpunt in namens Smals. Via deze link vind je meer informatie over de het onderzoek van Smals.