Recent waren we aanwezig bij de DataWorksSummit, ieder jaar georganiseerd door Hortonworks. In twee dagen tijd werden we bijgepraat over de ontwikkelingen bij het bedrijf. Het is ons in ieder geval duidelijk geworden dat er in de opensource-wereld van Hortonworks behoorlijk wat activiteit is. Niet alleen van Hortonworks zelf, maar ook van partners – sommige grote namen uit de industrie – die ermee bezig zijn. We zetten in dit artikel globaal het Hortonworks-platform uiteen.
Voor we wat dieper ingaan op wat we daadwerkelijk hebben gezien en gehoord tijdens DataWorksSummit, eerst even een klein beetje duiding rondom de naamgeving. De bijeenkomst waar we nu zijn, heette tot een aantal jaren geleden Hadoop Summit. Die naam dekte de lading echter niet meer. Het ging op den duur om veel meer dan alleen Apache Hadoop namelijk. Om het zo interessant mogelijk te houden voor bezoekers en sponsors, is er dus een andere naam bedacht.
Hadoop is natuurlijk nog wel een belangrijk onderdeel van waar het tijdens deze bijeenkomst primair om gaat, het platform van Hortonworks. Hortonworks is de naam die werd gekozen voor de Hadoop-spinoff van Yahoo in 2011. Hortonworks moest het op gaan nemen tegen partijen zoals Cloudera en MapR, die ook (delen van) Apache Hadoop gebruiken.
Global Data Management
Uiteindelijk draait het bij Hortonworks om Global Data Management. Een breed begrip waarbinnen meerdere componenten vallen. Hieronder zie je die verschillende componenten:
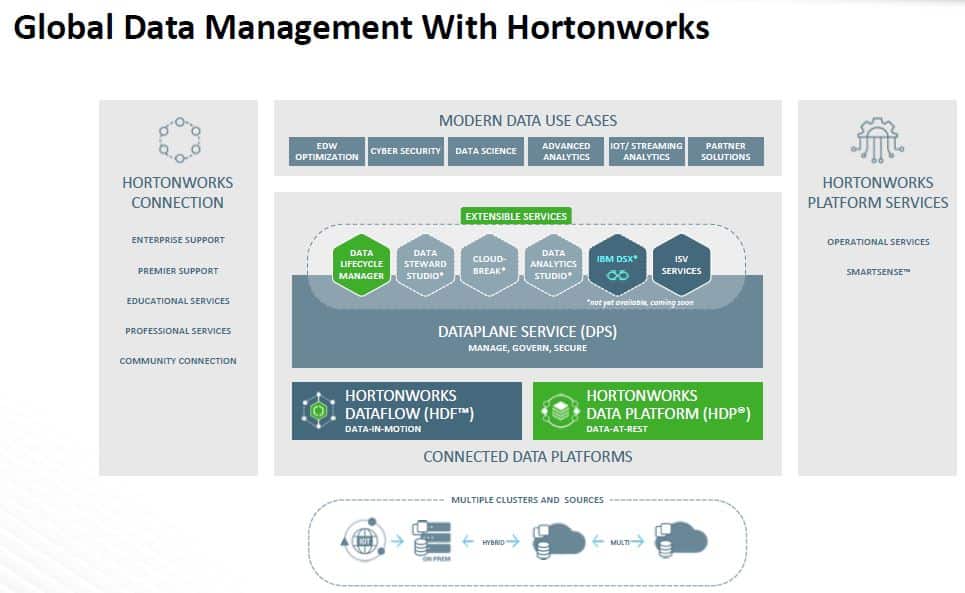
Op dit plaatje ziet een en ander er behoorlijk modulair uit. In de praktijk is het allemaal een stuk minder eenvoudig te vatten in een stacked, dus op het eerste gezicht hiërarchische weergave. Meerdere componenten lopen parallel aan elkaar, maar op verschillende sporen, of overlappen elkaar deels. Maar goed, als je die werkelijkheid schematisch wil weergeven, krijg je een onoverzichtelijk plaatje. Om een en ander wat beter te kunnen duiden, bespreken we in wat volgt de drie hoofdonderdelen van het Hortonworks-platform.
Hadoop als basis
Hortonworks is dus meer dan alleen Hadoop, dat mag duidelijk zijn. Sterker nog, Hadoop is eigenlijk alleen nog terug te vinden in een van de drie hoofdcomponenten die Hortonworks aanbiedt, Hortonworks Data Platform (HDP). HDP is eigenlijk waar het allemaal is begonnen. Dit is een platform voor het beheer van statische data, oftewel traditionele storage. De Hadoop-elementen HDFS (Hadoop Distributed File System) en YARN (Yet Another Resource Negotiator) vormen de basis van HDP. HDFS maakt de uitstekende schaalbaarheid van het platform mogelijk, iets wat uiteraard zeer belangrijk is als het gaat om big data. Het is daarnaast ook nog eens gunstig voor de portemonnee.
YARN maakte onderdeel uit van Hadoop 2 en verbeterde de verdeling van welke resources waarheen moesten aanzienlijk. Met andere woorden, je kunt er beter meerdere workloads tegelijkertijd door uitvoeren. Je kunt er eveneens relatief eenvoudig meerdere connectors mee adresseren. Hieronder zie je schematisch hoe een en ander is opgebouwd, inclusief de Apache-branches die per onderdeel ingezet kunnen worden:
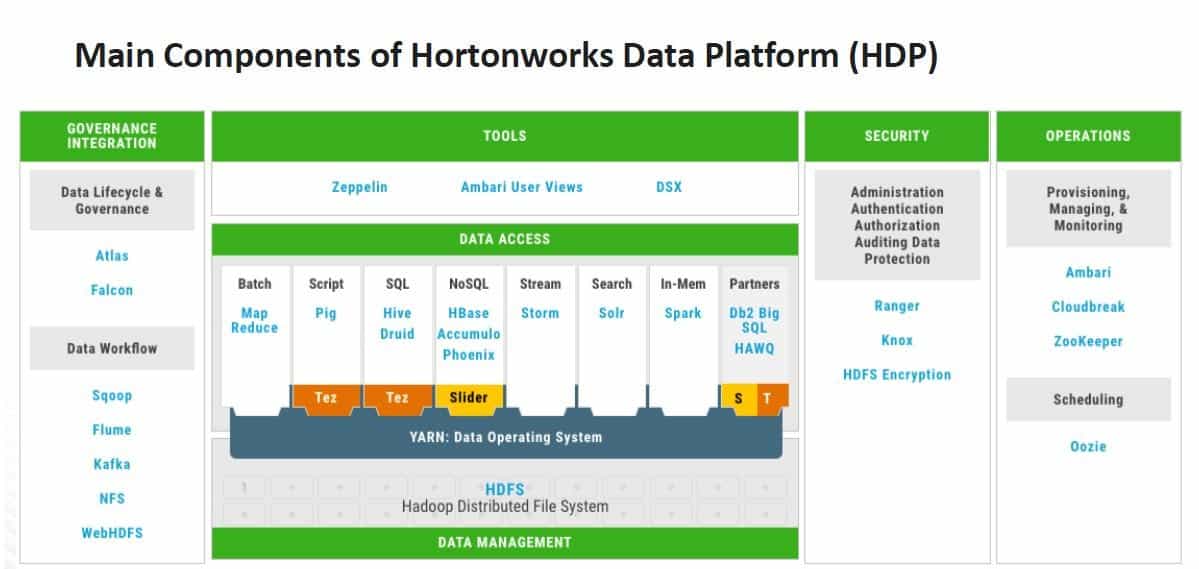
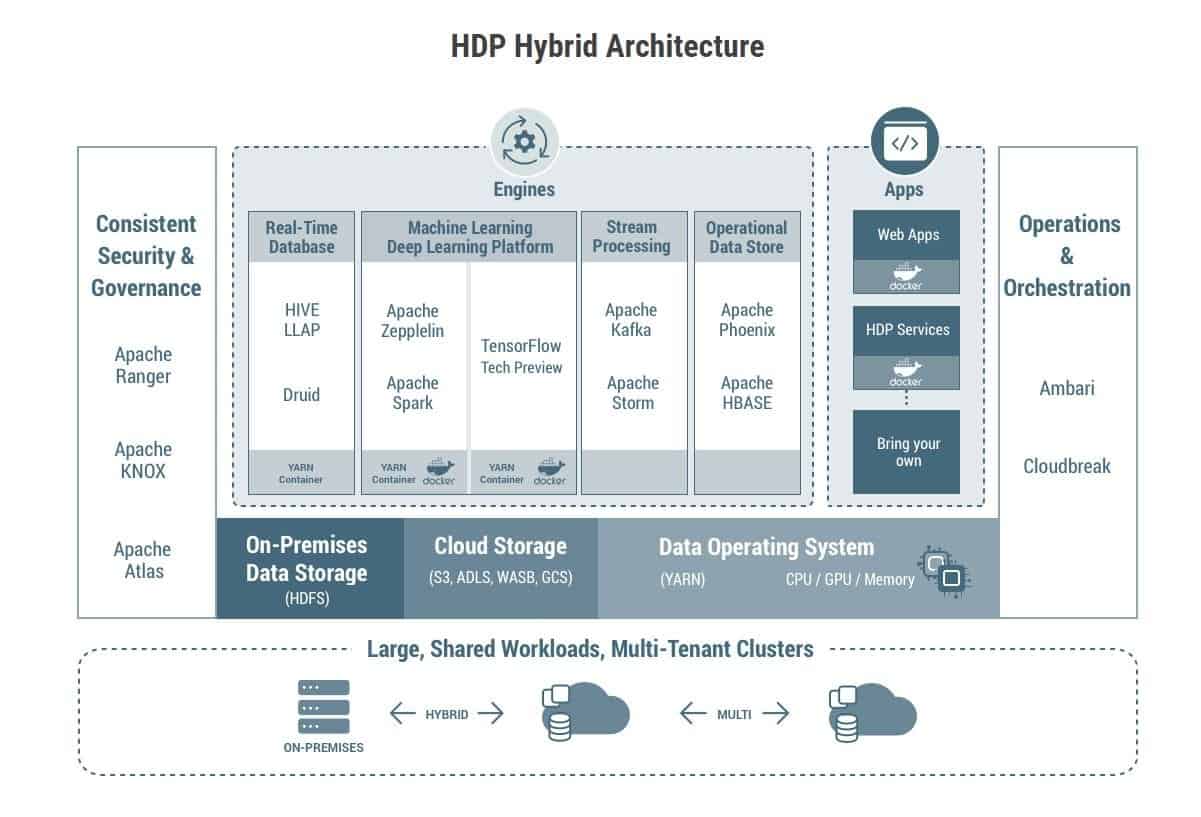
Inmiddels zijn we aanbeland bij HDP 3.0. Het meest in het oog springende van deze meest recente update, is dat men heeft geprobeerd om de gebruikservaring zo naadloos mogelijk te maken. Dat wil zeggen dat het niet uit moet maken of de data lokaal staat of in de cloud. Hieronder zie je hoe Hortonworks dit voor zich ziet. Via deze link kun je op de site van Hortonworks meer lezen over de nieuwste iteratie.
Verder bouwen met HDF
Met alleen HDP ben je er in de huidige wereld natuurlijk nog niet. Want het gaat tegenwoordig niet meer alleen om statische data (data-at-rest, zoals Hortonworks het noemt). Er is ook nog zoiets als bewegende data (data-in-motion). Daarvoor heeft Hortonworks de HDF-component ontwikkeld. Daarin kun je weliswaar nog altijd de nodige Apache-branches gebruiken, maar met het traditionele Hadoop heeft het verder niet veel meer te maken.
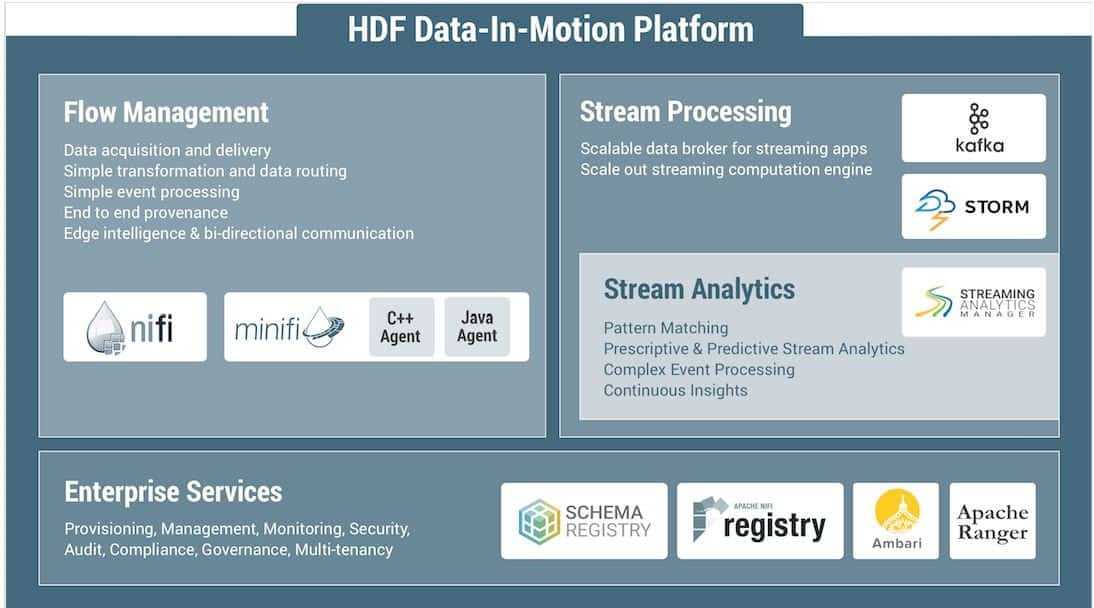
HDF staat voor Hortonworks DataFlow. Het geeft dus duidelijk aan dat we het hier over bewegende data hebben. Je moet dan denken aan streaming data, maar bijvoorbeeld ook data van IoT-sensoren. Dat laatste was dan ook iets waar stevig op ingezet wordt. Hortonworks noemt de toevoeging van HDF zelf het begin van Hortonworks 2.0.
Meer doen met data
Bij HDF gaat het niet meer alleen om het simpelweg kunnen opslaan van data. Er wordt ook daadwerkelijk iets gedaan met de data. Dinesh Chandrasekhar, de Director of Product Marketing die zich primair bezighoudt met HDF, maakt onderscheid tussen het transformeren en het verrijken van de data. Deze zaken zijn volgens hem mogelijk, omdat je er allerlei bronnen aan kunt koppelen. Bronnen kunnen IoT-sensoren zijn, maar ook een applicatie die ergens in de AWS-cloud draait. Het koppelen van bijvoorbeeld een weerdienst aan het verwerken van een bepaalde dataset kan ertoe leiden dat je veel relevantere analyses uit kunt voeren. Je verrijkt de data dan. Daar kun je onder andere ook machine learning voor gebruiken.
Het HDF-platform is volgens Chandrasekhar vooral erg interessant, omdat het verbinding kan maken met zo goed als alle protocollen die je maar kunt verzinnen. Het maakt het platform vrijwel agnostisch voor waar data vandaan komen. Zeker binnen IoT – waar enorm veel protocollen en dus weinig standaarden zijn – is dat belangrijk.
NiFi
Een belangrijke component binnen HDF is Apache NiFi. Dit onderdeel zorgt ervoor dat de data binnengehaald wordt en naar de juiste bestemming gestuurd wordt. Het zorgt ook voor het koppelen van verschillende bronnen. Binnen IoT wordt er soms ook gevraagd naar een kleine variant, die meteen op een IoT-apparaat wordt geïnstalleerd. Daarvoor is MiNiFi ontwikkeld. Zeker als je heel veel apparaten hebt die je in realtime wilt monitoren, om bijvoorbeeld eveneens in realtime te kunnen reageren, biedt MiNiFi de nodige voordelen. Je weet immers bij binnenkomst precies waar de data vandaan komen en kunt er meteen op inspringen. De zelfrijdende auto is een voorbeeld van een endpoint dat uitermate geschikt lijkt voor MiNiFi.
Naast de distributie van de data, is er uiteraard ook nog de verwerking en de analyse ervan. Hiervoor worden deels weer de nodige Apache-branches gebruikt, die we ook al tegenkwamen bij HDP. Tot slot is er ook gedacht aan het beveiligen en beheren van alle bewegende data. We komen hier bekende Apache-onderdelen als Ambari en Ranger tegen.
Je moet HDF en HDP overigens niet als twee strikt gescheiden onderdelen zien van de architectuur van Hortonworks. Er is wel degelijk de nodige overlap. Onder andere als het gaat om de te gebruiken Apache-branches.
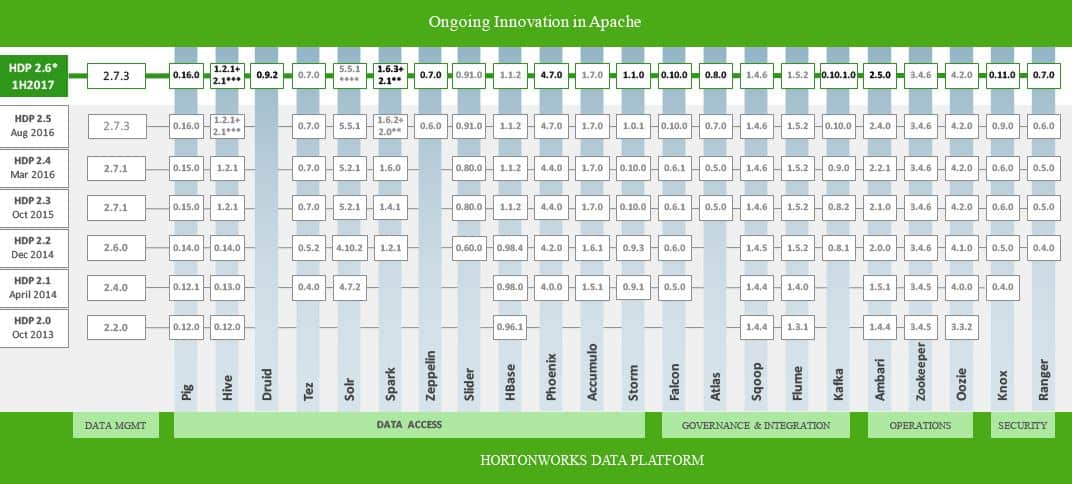
Hortonworks 3.0
Waar HDF in 2015 het begin van Hortonworks 2.0 inluidde, zijn we in 2018 aanbeland bij versie 3.0. Uiteraard is er weer een nieuwe laag met een nieuwe naam bedacht voor versie 3.0: DataPlane Service (DPS). Mocht je uit de software-defined-wereld komen, dan brengt deze term wellicht wat verwarring met zich mee. Want ondanks de naam, hebben we hier toch echt te maken met iets wat eigenlijk niets van doen heeft met de ‘traditionele’ dataplane in software-defined omgevingen zoals je die aantreft bij software-defined networking en Hyper-Converged Infrastructure. Het is overduidelijk onderdeel van de control plane, al gaat het onderscheid tussen dataplane en controlplane bij Hortonworks niet helemaal op overigens. Een erg handig gekozen naam is het in ieder geval niet wat ons betreft.
Bij DPS draait het in de basis om beheer, security en governance van data. Via DPS kun je aangeven wat er wel en niet mag gebeuren met de data die in HDP en HDF worden beheerd en bewerkt. Je kunt er op dit moment twee toepassingen aan koppelen: Data Lifecycle Manager en Data Steward Studio. In theorie zit er geen limiet aan het aantal applicaties dat je kunt koppelen aan deze laag.
Hortonworks ontwikkelt zelf applicaties voor deze laag, maar werkt ook samen met andere leveranciers. Zo komt er binnenkort een versie van IBM Data Science Experience (DSX) beschikbaar voor DPS. Hiermee krijgen datawetenschappers de mogelijkheid om met meerdere talen aan de slag te gaan (RStudio, Spark, Python) en krijgen ze toegang tot het Watson Data Platform en daarmee dus machine learning. Dit alles uiteraard toegepast op de te beheren data. Uiteindelijk is IBM DSX op Hortonworks DPS ook een data lifecycle manager.
Data Steward Studio
Met het oog op de onlangs in werking getreden GDPR, is met name Data Steward Studio een belangrijke toevoeging. Je kunt dit het best zien als een nieuwe generatie van Apache Atlas, dat we kennen uit HDP. Het draait hierbij om governance en compliance, twee belangrijke termen met het oog op GDPR. Volgens Hortonworks zelf probeert men hiermee niet partijen zoals Collibra naar de kroon te steken overigens. Dat soort propriëtaire oplossingen blijven nodig, maar je kunt Data Steward Studio er wel mee samen laten werken.
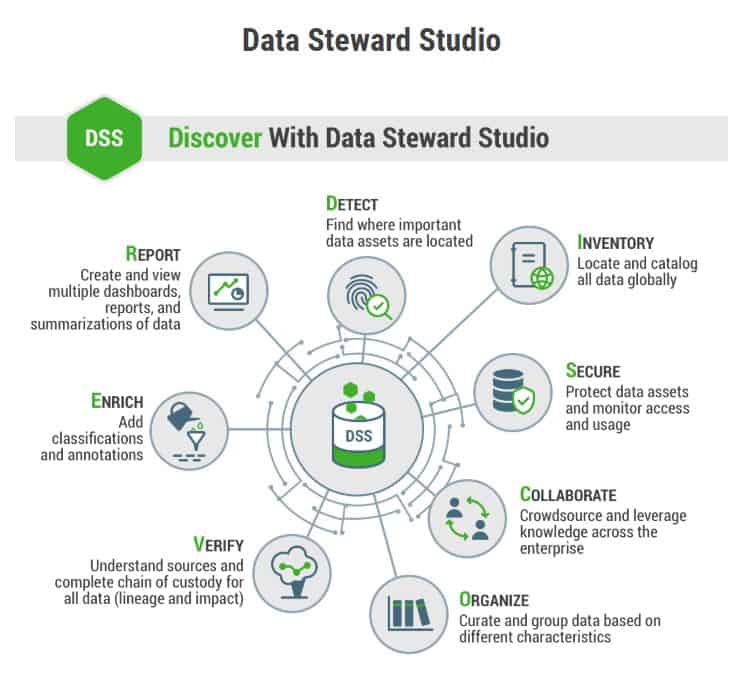
DPS is niet eenvoudig in een gelaagde weergave van het Hortonworks-platform te vangen. Het ligt niet boven of onder HDP en HDF, maar meer ertussen. Het hoort tussen on-prem en de cloud in, maar neemt niet alle verbindingen met de cloud voor zijn rekening bijvoorbeeld. HDF verbindt in het geval van IoT-sensoren ook rechtstreeks met de cloud, maar doet dat met een ander doel en dus op een ander niveau. Waar HDF werkt met daadwerkelijke data, werkt DPS met metadata. Uiteindelijk moet je DPS zien als datgene wat er meer een geheel van maakt, vooral als het gaat om datamanagement, is onze indruk na enkele dagen in de Hortonworks-wereld vertoefd te hebben.
Hortonworks in actie
Om inzicht te krijgen in waar Hortonworks voor gebruikt wordt, hebben we ook geprobeerd om mensen te spreken die het platform ook daadwerkelijk gebruiken. Zo raakten we in gesprek met iemand van Quanam. Dit bedrijf (of eigenlijk verzameling bedrijven) zegt wellicht niet iedereen iets, omdat het vooral kantoren heeft in Latijns-Amerika. Ze doen echter wel degelijk wereldwijd projecten, ook hier in onze regio.
Het doet er op zich ook niet zoveel toe waar het bedrijf vandaan komt. Interessanter is om te zien waar ze het Hortonworks-platform voor gebruiken. Quanam zet onder andere big data projecten op, samen met partners. Eentje daarvan heeft te maken met genomica/genomics, oftewel de studie van genomen. Genomen kunnen ons veel vertellen over de ontwikkeling van de mensheid, maar bijvoorbeeld ook over ziektebeelden.

Als je bedenkt dat het zogeheten exome (1 procent van een genoom, maar verantwoordelijk voor zo’n 85 procent van de mutaties die worden geassocieerd met ziektes) van een genoom al 300 GB beslaat als het getranscribeerd is, dan heb je serieus veel opslag nodig. Daarnaast stelt het formaat uiteraard ook de nodige eisen aan de rekenkracht, zeker als je in het achterhoofd houdt dat het hier gaat om ongestructureerde data. Te veel compute is dan eigenlijk niet mogelijk.
Twee sets resultaten
Al die compute is uiteindelijk nodig om twee sets resultaten te genereren. Allereerst wil men een resultaat hebben dat aangeeft of iets pathogenisch is. Dat wil zeggen, of er aanwijzingen in het genoom (of eigenlijk het exome) zijn die duiden op een specifiek ziektebeeld. Dit kun je zien als het gedeelte dat rechtstreeks gericht is op de patiënt, die graag wil weten of er iets met hem aan de hand is of dat er iets op stapel staat.
De tweede set resultaten heeft te maken met hoe snel en eenvoudig specialisten bij de uitkomsten van het onderzoek kunnen. Er moet dus ook een soort anthologie uit komen rollen, waarbij er meteen referenties gelegd worden naar specifieke literatuur. De samenvattingen van de literatuur wordt door middel van Natural Language Processing aan de juist onderwerpen en dergelijke gekoppeld. Daarbij wordt er niet alleen gekeken naar letterlijke verwijzingen, maar ook naar in eerste instantie minder voor de hand liggende connecties. Hier komt ook een zekere mate van machine learning aan te pas. Dat moet ook wel, want er zit veel variatie tussen mensen.
Keuze voor Hortonworks
Uiteindelijk is men in eerste instantie bij Hortonworks terechtgekomen, omdat de opslagcapaciteit extreem goed schaalbaar is. Dat is bij het werken met dit soort grote hoeveelheden data, waar alleen maar meer data uit gegenereerd wordt, natuurlijk van cruciaal belang. Je weet vooraf ook niet hoeveel je nodig hebt, dus is schaalbaarheid van doorslaggevend belang.
Sommige databases zijn daarnaast zo’n 500 miljoen records groot. Daarvoor moet je data warehousing uiteraard ook goed op orde zijn. Bij Quanam zijn ze zeer te spreken over de meerwaarde die Apache Hive op dit vlak kan leveren. Om het verwerken van data zo snel mogelijk te laten verlopen, gebruikt men Apache Spark (op YARN in HDP). Deze branch richt zich op het verwerken van data in het geheugen. Het gaat dan vooral om processen die heel vaak herhaald moeten worden.
Uiteraard is er bij Quanam ook gedacht aan de gevoeligheid van de data. Het is namelijk lastig om data voor te stellen die persoonlijker is dan de genetische opbouw van mensen. Daarvoor is men uitgekomen bij Apache Spark voor access control en Apache Atlas voor compliance.
Is de toekomst opensource?
De gang zit er op dit moment goed in, zoveel is duidelijk als we naar de cijfers van Hortonworks kijken. Er werken zo’n 1100 mensen bij het bedrijf en in het vierde kwartaal van 2017 is een omzetgroei gerealiseerd van 61 procent (jaar-op-jaar). In dat kwartaal bedroeg de omzet 75 miljoen dollar. De grafiek van de omzetontwikkeling ziet eruit zoals ieder bedrijf die graag ziet; continu gestaag stijgend. Het bedrijf is volgens wat het naar buiten brengt ook ‘cashflow-positive‘, wat inhoudt dat er meer geld binnenkomt dan eruit gaat.
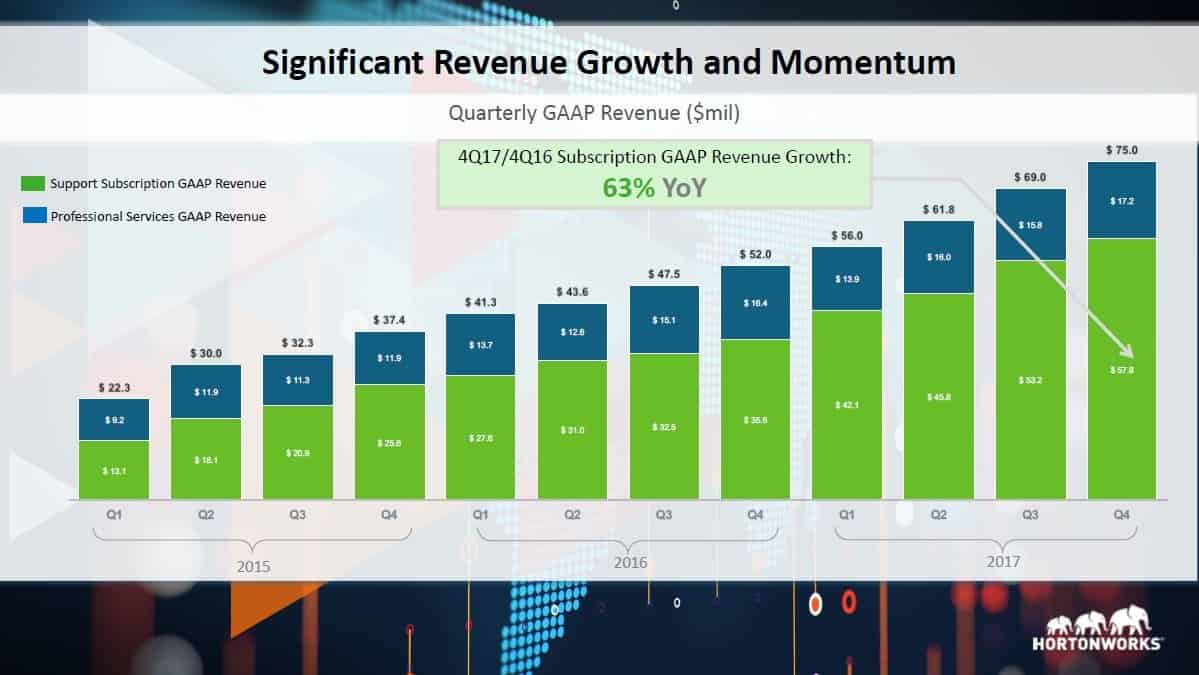
Als we ook eens naar de rest van de markt kijken, dan dringt zich de vraag op of de toekomst meer en meer opensource gaat worden. In het algemeen lijken bedrijven die zich hiermee bezighouden het goed te doen in ieder geval. Een partij zoals Red Hat had een paar kwartalen terug voor het eerst in het bestaan een omzet van meer dan een miljard dollar. We zien daarnaast ook meer samenwerkingen tussen bedrijven die je traditiegetrouw onder de closed source noemer zou plaatsen met opensource partijen. Een mooi voorbeeld hiervan is de samenwerking tussen Juniper Networks en Red Hat.
Opensource zorgt voor samenwerking
Het lijkt er dus op dat opensource het nog wel even goed blijft doen. Op zich is dat niet zo gek, omdat opensource vaak ook partnerships en samenwerking impliceert. En laat dat nu juist een van de trends zijn in de huidige markt. Meer en meer partijen komen erachter dat ze het niet alleen kunnen of willen. Of het nu Palo Alto Networks is dat zijn data lake openstelt voor third-party ontwikkelaars, of de samenwerkingen die Lenovo aangaat met verschillende software-partijen.
Wat de toekomst van opensource ook zal zijn, je kunt er in ieder geval van op aan dat je er op Techzine over wordt geïnformeerd. Want wij zullen partijen zoals Hortonworks, maar ook Red Hat en andere wellicht iets minder in het oog springende partijen blijven volgen.