
HPE wil zich onderscheiden van de concurrentie met een AI-gericht aanbod waar een full stack, AI-native architectuur centraal staan. Natuurlijk speelt Nvidia een grote rol in dat nieuwe verhaal.
“Wat zal de toekomst brengen?” HPE’s CEO Antoni Neri stelt de vraag retorisch. “Het antwoord is duidelijk AI. AI wordt disruptiever dan mobiele telefoons en de cloud. Het is de belangrijkste technologie van onze tijd”, voorspelt hij.
Dat stelt HPE tijdens Discover Barcelona voor een belangrijke uitdaging. Het bedrijf moet zijn eigen sterktes uitspelen, maar kan en wil tegelijkertijd de AI-hype niet naast zich neerleggen. Net als zowat iedere technologiespeler die zich profileert sinds de lancering van ChatGPT exact één jaar geleden, ziet het bedrijf zich gedwongen om een belangrijke gastrol te voorzien voor Nvidia. HPE mag zich dan hervormd hebben tot een service-specialist, het DNA van het bedrijf bevat toch hardwaredozen en als je AI-workloads in die dozen wil passen, dan kan je niet om Nvidia-componenten heen.
AI-architectuur
Dat creëert een perceptieprobleem: als het grote nieuws van iedereen en zijn kat een succesvolle AI-gerichte samenwerking met Nvidia is, wat is dan nog de meerwaarde van individuele spelers? HPE heeft een antwoord klaar dat steekhoudt, maar soms toch iets minder coherent klinkt dan we misschien zouden wensen.
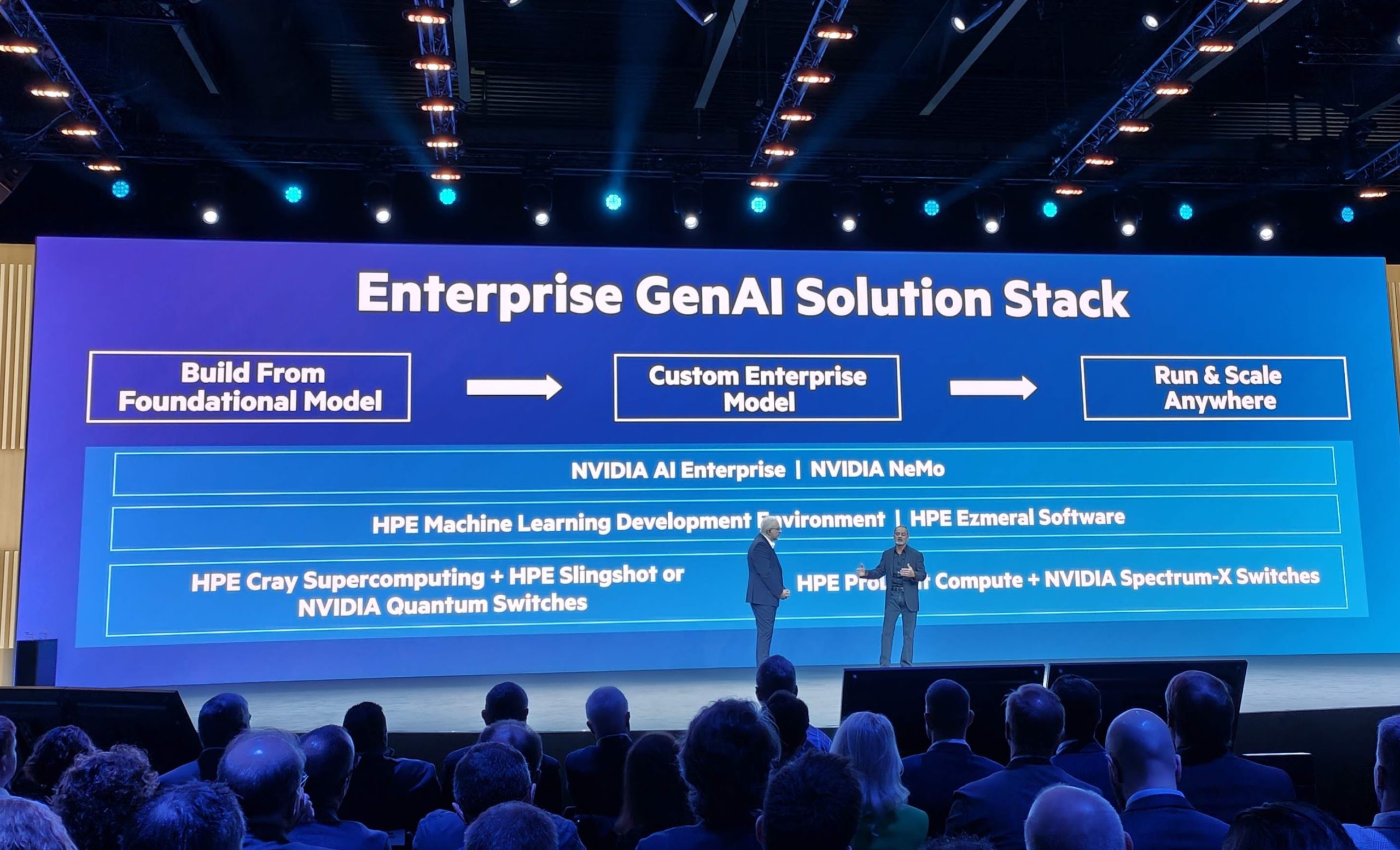
De kern van de zaak is de zogenaamde AI-native architectuur op maat van generatieve AI. HPE stelt vast dat fundamenteel andere workloads fundamenteel andere hardware vereisen. Die AI-native architectuur neemt de vorm aan van een full-stack oplossing waar HPE samen met Nvidia van de hardware tot de software een oplossing biedt om AI-modellen te trainen, te tweaken en te draaien, en dat in een hybride context.
Opslag
Langs de hardwarekant zien we op HPE Discover Barcelona twee belangrijke aankondigingen. Langs de ene kant horen we dat AI begint bij data, en data vereist snelle opslag. Het flash-platform HPE GreenLake voor File Storage krijgt daarom enkele upgrades. HPE biedt ondersteuning voor drives van 30 TB, goed voor een vermeerdering van de capaciteitsdichtheid met factor 1,8. De totale bruikbare capaciteit schaalt de lucht in tot 250 PB.
Een datadoos alleen kan je weinig mee aanvangen, dus ook langs de connectiviteitskant krijgt de oplossing een boost. HPE GreenLake voor File Storage ondersteunt nu Nvidia Quantum-2 InfiniBand en Nvidia GPUDirect, voor GPU-centrisch rekenwerk op grote hoeveelheden gegevens. “GPU’s zijn duur”, zegt Patrick Osborne, SVP en GM HPE Storage daarover. “Ze moeten zo efficiënt mogelijk gevoed worden.”
Inferentie
Wat gaan we dan voeden? Wat dacht je van een rack gevuld met HPE ProLiant DL380a Gen 11-servers. De hardware is ontwikkeld met – hoe kan het ook anders – Nvidia, gebouwd rond Nvidia L40S GPU’s. Dat zijn relatieve mainstream-GPU’s die AI-workloads kunnen ondersteunen en ideaal zijn voor inferentie, maar vlotter van de band rollen van de heel krachtige (en dure) Hopper-chips.
De server krijgt verder Nvidia BlueField-3-DPU’s mee en Nvidia Spectrum-X-networking. Die laatste toevoeging maakt duidelijk dat HPE op schaal denkt, aangezien Spectrum-X de aaneenschakeling van nodes en racks in een cluster mogelijk maakt.
“De oplossing is speciaal ontwikkeld voor veelvoorkomende AI-workloads”, zegt Neil MacDonald, EVP en GM voor Compute. “De hardware is geoptimaliseerd voor modellen zoals Llama-2-70B.” Met de server kan je modellen finetunen en gebruiken. Dat kunnen vooraf getrainde modellen zijn, zoals de exemplaren die HPE enkele maanden geleden aankondigde.
“Dit is een turnkey-oplossing voor de honderdduizenden bedrijven die niet hun eigen modellen gaan bouwen.”, zegt Manuvir Das, VP Enterprise Compute bij Nvidia. “Iemand anders doet 99 procent van het werk door een funderingsmodel te trainen. Een bedrijf neemt dat model, en doet de laatste percent van het werk door het model te tunen met eigen data. Vervolgens wordt het hun eigen model. Dat laat deze oplossing toe.”
Het rack dat HPE vandaag in de verf zit, is dus iets instapvriendelijker dan de aankondiging van enkele weken eerder waarbij HPE samen met Nvidia krachtige hardware om zelf modellen te trainen lanceerde. Die oplossing was gebaseerd op de HPE Cray EX2500-supercomputer en nieuwe (de facto quasi onbeschikbare) Nvidia GH200 Grace Hopper-superchips. De HPE ProLiant DL380a Gen 11 is niet bedoeld om modellen te trainen, wel voor inferentie en tuning.
Software-stack
Een hele stack is meer dan de hardware. De HPE ProLiant DL380a-servers draaien daarom braaf de HPE Machine Learning Development Environment en dataplatform HPE Ezemeral. Helemaal bovenaan de stack vinden we opnieuw Nvidia met z’n AI Enterprise-ecosysteem en de NeMo-frameworks.
Met de Nvidia-suite kan HPE zich niet differentiëren, dus ligt de focus op de HPE Machine Learning Development Environment. Die is niet alleen beschikbaar op eigen servers, maar ook als managed service bij cloudproviders AWS en Google. HPE meent het als het zegt dat het in hybride gelooft: in de omgeving kan je AI- en ML-modellen trainen en dat kan nu dus in een hybride context. “We zijn hybride by design”, zegt Neri daarover.
AI-native hybride-architectuur
Samengevat pakt HPE op Discover uit met verbeteringen in hardware stoelen op een nauwe samenwerking met Nvidia. Die hardware bestaat niet in een vacuüm, maar maakt deel uit van een platformaanpak waarbij HPE via software edge, datacenter en cloud aan elkaar lijmt en data samenbrengt. Modellen trainen en tunen gebeurt via de HPE ML Development-omgeving, die nu ook in de cloud beschikbaar is. Verbeteringen in HPE Ezmeral helpen om de data tot bij de algoritmes te krijgen. Ezmeral werkt voortaan bovendien beter samen met GPU’s.
Wie bij HPE aanklopt, kan de hele stack krijgen. De rack-oplossing met ProLiant-servers is daar een concreet voorbeeld van. Die oplossing combineert hardware met de nodige software van zowel HPE als Nvidia. HPE denkt dat die stack-aanpak met een architectuur die vertrekt vanuit AI zal volstaan om zijn aanbod, dat net als dat van alle concurrenten gebouwd is met Nvidia, te onderscheiden.
Dat klinkt aannemelijk, al missen we toch een beetje stoomlijning. De link tussen storage en compute blijft bijvoorbeeld vaag, net als de echte integratie van alle softwarecomponenten in. Binnen de context van GreenLake kondigde HPE een dag na deze aankondiging wel een duidelijkere connectie tussen de twee aan.
lees ook
HPE vereenvoudigt hybride AI-aanbod in GreenLake met gestructureerde pakketten
Alle componenten worden hier naar voren geschoven als deel van een totale stack, maar staan los van dat verhaal toch ook redelijk op zichzelf. HPE combineert voor een stuk wat het al heeft, wat ons dan weer doet afvragen of de AI-native-architectuur echt wel zo fundamenteel anders is dan we op het podium horen.