
Natural Language Processing (NLP) is een vorm van artificiële intelligentie die ervoor zorgt dat computers menselijke taal kunnen ontleden. De computer kan de taal niet begrijpen zoals mensen maar leert associaties tussen combinaties van woorden en letters. NLP-technologieën zijn bezig aan een sterke opmars in het dagelijkse leven: denk aan chatbots, virtuele assistenten zoals Siri, of automatische vertaaltools. In het Engels staat de technologie al ver, maar hoe zit dat in het Nederlands? En hoe ga je zelf aan de slag met Nederlandse taalmodellen?
NLP is een belangrijke component in toepassingen zoals chatbots en voicebots. Het kan ook ingezet worden om data te annoteren en bijvoorbeeld een knowledge graph te verrijken, wat dan weer beter kennisbeheer en -ontsluiting mogelijk maakt. Wie een beetje kan programmeren, kan al snel met NLP experimenteren. Veel code is open source, en er zijn talloze goede tutorials te vinden met educatieve notebooks in Jupyter of Google Colab. Alleen beperken deze zich vaak tot wereldtalen. Regelmatig lees je over de spectaculaire vooruitgang van NLP in het Engels, zoals het AI-taalmodel GPT-3, maar over minder courante talen is veel minder bekend. Wie NLP probeert toe te passen in het Nederlands, botst onvermijdelijk op een aantal obstakels.
SpaCy is een bekende open-source Python library voor NLP. Ze is gebruiksvriendelijk en verbergt veel van de onderliggende complexiteit van NLP of de achterliggende Machine Learning frameworks zoals PyTorch of Tensorflow. Sinds versie 3.0 worden transformer deep learning architecturen ondersteund. Deze liggen aan de basis van de meest succesvolle recente taalmodellen. Smals Research gebruikt deze versie van SpaCy voor al wat volgt. Alternatieven voor SpaCy zijn onder andere Stanza en Flair.
Entiteiten herkennen in het Engels versus het Nederlands
Een ingebouwde functionaliteit van de taalmodellen van SpaCy is Named Entity Recognition (NER), het herkennen van entiteiten, zoals plaatsnamen en datumaanduidingen, in een tekst. Bij elk taalmodel hoort een labelschema dat alle categorieën toont die het model kan herkennen, waaronder DATE, TIME, PERCENT, PERSON (eigennamen) of PRODUCT. Via hun tutorial kan NER gemakkelijk worden uitgetest in zowel het Engels als het Nederlands.
Resultaat in het Engels:
import spacy
from spacy import displacy
nlp = spacy.load(“en_core_web_sm”)
doc = nlp(“Apple buys a French company for $1 billion.”)
displacy.render(doc, style=”ent”)
{kind=link}

Apple wordt herkend als ORG (organisatie), French als NORP (nationaliteit of religieuze/politieke groep) en $1 billion als een geldhoeveelheid.
Resultaat in het Nederlands:
import spacy
from spacy import displacy
nlp = spacy.load(“nl_core_news_sm”)
doc = nlp(“Apple koopt een Frans bedrijf voor $1 miljard.”)
displacy.render(doc, style=”ent”)

In het Nederlands wordt Apple plots aangeduid als persoon en 1 als telwoord. De kleine taalmodellen annoteren de zin dus incorrect. De grote versie van het taalmodel is accurater, maar gaat nog steeds de mist in bij het dollarteken. Ook al lijken de taalmodellen enkel te verschillen qua taalcode, er is geen garantie dat wat werkt in de ene taal even goed werkt in een andere taal. Het repliceren van Engelstalige NLP-succesverhalen in een andere taal, is dus geen kwestie van eens snel te copy-pasten.
{kind=link}
Waar komen de verschillen vandaan?
Een blik op de onderliggende automatische grammaticale analyse maakt een en ander duidelijk:
displacy.render(list(doc.sents), style=”dep”)
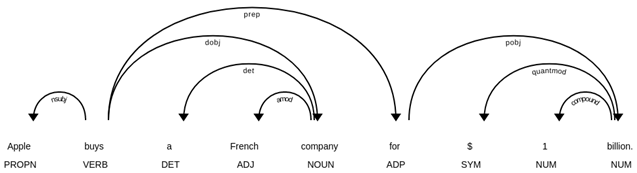
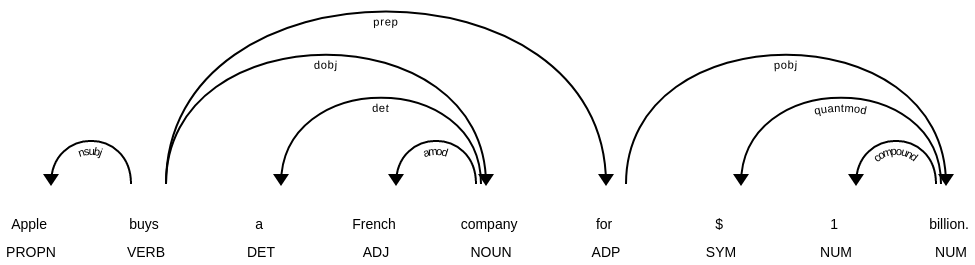{kind=link}
{kind=link}
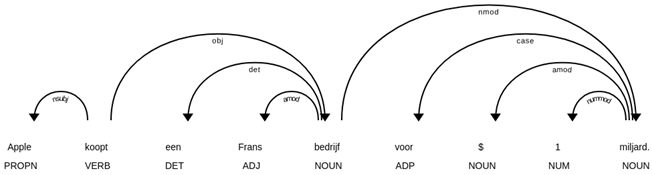
De betekenis van alle afkortingen voor woordsoorten en -functies staan op de website van Universal Dependencies. Hieruit blijkt het volgende:
- billion wordt aanzien als telwoord, miljard als zelfstandig naamwoord.
- $ wordt in het Engels als symbool geannoteerd, maar in het Nederlands als naamwoord.
- In het Engels is “for $1 billion” afhankelijk van het werkwoord en dus een bijwoordelijke bepaling, in het Nederlands is “voor $1 miljard” afhankelijk van het naamwoord bedrijf.
- Apple wordt in beide talen correct aangeduid als eigennaam en onderwerp, dus de grammaticale analyse alleen is niet genoeg om het onderscheid te verklaren.
SpaCy‘s taalmodel voor het Nederlands ziet de zaken dus anders dan dat voor het Engels. De documentatie ervan laat zien dat de componenten tagger en parser, die de zinsontleding voor hun rekening nemen, ook heel anders georganiseerd zijn in het Nederlands en veel complexer lijken dan voor het Engels. Ook blijkt de dataset waarop de grammaticale analyse is getraind, anders te zijn: OntoNotes 5 voor het Engels, en LassySmall 2.5 en Alpino uit Universal Dependencies voor het Nederlands.
De achterstand van Nederlandstalige datasets
Er is ongeveer tien keer minder trainingsdata beschikbaar voor het Nederlands dan voor het Engels. Ook De Standaard merkte dit grote verschil op: de trainingsdata van GPT-3 bestaan voor 92% uit Engelse en voor amper 0,35% uit Nederlandse tekst. Naast minder trainingsdata is er ook nog het uitgebreidere labelschema in de woordsoort-tagger. Hierdoor zijn er minder voorbeelden per label beschikbaar. Ook is het bronmateriaal minder gevarieerd: enkel oude nieuws- en Wikipedia-artikelen. Op het moment van schrijven is het beste (ingebouwde) Nederlandse taalmodel in SpaCy dan ook minder accuraat in detectie van woordsoort (part-of-speech tags, 95%), zinsstructuur (labeled dependencies, 82%) en entiteiten (F-score 77%) in vergelijking met hun slechtste Engelse taalmodel (resp. 97%, 90%, 84%) – laat staan dat het in de buurt komt van het beste Engelse taalmodel (resp. 98%, 94%, 90%). Dat laatste is weliswaar een gloednieuw transformer-model. Wellicht zal dit ook voor het Nederlands voorzien worden in SpaCy, aangezien er al enkele beschikbaar zijn in de transformers model hub.
Om de achterstand structureel in te halen, zijn grotere Nederlandstalige datasets nodig om taalmodellen te trainen. Dat vergt veel middelen en tijd. Misschien kan dit sneller gaan via gedeeltelijke automatisering met behulp van al bestaande automatische annotatie en crowdsourcing. Voor het trainen van word embeddings / vectors hoeft de tekst niet geannoteerd te zijn. Daarvoor bestaan ook in het Nederlands wel erg grote datasets, waaronder Wikipedia dumps of Common Crawl. Ook gebeurt er onderzoek naar few-shot learning, waarvoor slechts enkele geannoteerde voorbeelden voldoende zouden zijn, maar er is nog volop debat over wanneer en onder welke voorwaarden dat wel of niet kan werken. Ondertussen zijn de bestaande taalmodellen zeker niet nutteloos: ze kunnen gemakkelijk worden getweakt voor eigen toepassingen.
Hoe zelf een taalmodel verbeteren?
Wat kan je vandaag al doen om fouten te reduceren? SpaCy is als library modulair opgezet en iedere component van de tekstverwerkingspijplijn kan worden aangepast. Je zag eerder dat het Engelse billion wel als getal werd gezien, maar het Nederlandse miljard niet.
Kijk eerst naar de taalspecifieke uitzonderingen die SpaCy definieert. Daarin zie je dat in de lexicale attributen het woord miljard wel degelijk als getal wordt aangeduid, net zoals in het Engels. Alleen samengestelde getallen (“drieëntwintig”) worden op moment van schrijven nog niet zo geannoteerd in het Nederlands – een punt van verbetering wat de analyse van het Nederlands in SpaCy betreft!
{kind=link}

De woordsoorten worden toegekend door een Morphologizer in de pijplijn: dit is een component die getraind is en waarvan de uitkomst dus afhangt van de trainingsdata. En inderdaad, als je de inhoud van UD_Dutch-LassySmall en UD_Dutch-Alpino erop naleest, zijn woorden zoals miljoen en miljard er enkele keren in terug te vinden, consistent geannoteerd als NOUN.
Het is mogelijk een eigen versie van de trainingsdata te maken waarin dat anders is en zo een geheel nieuwe Morphologizer component te trainen. Voor dergelijke kleine aanpassingen is een alternatief ook om een op maat gemaakte component toe te voegen aan de pijplijn, die de automatische annotatie door zo’n standaard taalmodel aanpast of aanvult waar nodig. In dit geval kan een zelfgeschreven AttributeRuler ingevoerd worden achter de Morphologizer, die de woordsoort aanpast van NOUN naar NUM voor NOUNs waarbij “token.like_num == True“:
ruler = nlp.add_pipe(“attribute_ruler”, name=”fix_num”, after=”morphologizer”)
detect = [[{“POS”: “NOUN”, “LIKE_NUM”: True}]]
assign = {“POS”: “NUM”}
ruler.add(patterns=detect, attrs=assign)

Hoe NER updaten zonder catastrophic forgetting?
{kind=link}
De Named Entity Recognition component, die Apple een persoon noemde in het Nederlands, is ook een aparte component in de pijplijn die de gebruiker kan aan- of uitschakelen, bijtrainen of in zijn geheel vervangen. Het is niet mogelijk om een lijstje van patronen te maken waarmee alle mogelijke bedrijfsnamen herkend zouden kunnen worden. Trainen op voorbeelden is hier dus onvermijdelijk. De NER-component kan hier blijkbaar enkele voorbeeldzinnen over bedrijfsacquisities gebruiken, om te leren dat niet enkel personen iets kunnen kopen.
SpaCy heeft sinds kort een hele projectarchitectuur uitgebracht die het beheer en het uitvoeren van trainingsprojecten voor taalmodellen sterk vereenvoudigt. Je hoeft maar een van de templateprojecten te klonen en aan te passen aan je noden:
python -m spacy project clone pipelines/ner_demo_update
Dit commando downloadt een kant-en-klaar project dat out-of-the-box werkt. In het bestand project.yml maak je de nodige aanpassingen aan de configuratie: de taal en het basismodel wijzigen naar het Nederlands, eventueel de GPU inschakelen, enz. Het project.yml bestand werkt zoals een Makefile: het definieert verschillende commando’s voor de voorbereiding van de data, het samenstellen van de trainingsconfiguratie, het uitvoeren van de training, het exporteren en packagen van het resulterende model en het schoonmaken van de bestandsstructuur. Je kan er zelf onderdelen aan toevoegen. Er zijn ook mogelijkheden om het resultaat te visualiseren of via een API te publiceren, via integraties met libraries zoals streamlit, FastAPI, weights&biases en ray.
Dan moet je enkel nog trainingsdata in de map assets zetten. Er zijn allerlei tools beschikbaar om tekst of andere data te annoteren: die van UD zelf, LabelBox, Doccano… maar buiten SpaCy’s eigen Prodigy bieden weinig tools directe ondersteuning voor SpaCy. Het kan nog nodig zijn om een eigen script te maken om data te converteren naar een ondersteund formaat, en dat is met een extra lijntje code in project.yml snel ingevoegd. Gelukkig is het formaat gebruikt in het demoproject relatief eenvoudig en kan je snel manueel een JSON-file schrijven. Ter illustratie zie je hieronder enkele titels van recente artikels op Tweakers.net:
[
[“OnePlus 9 Pro met nieuwe Sony-sensor verschijnt eind maart voor 899 euro.”, {“entities”:[[0,7,”ORG”],[25,29,”ORG”],[64,72,”MONEY”]]}],
[“Gerucht: Discord voert gesprekken met Microsoft over mogelijke overname.”,{“entities”:[[9,16,”ORG”],[38,47,”ORG”]]}],
…
]
Om aan te tonen dat de context bepalend is om een woord als een specifieke entiteit te markeren, vermeldt geen enkele van de voorbeeldzinnen Apple. Eens alle onderdelen van het project zijn gedefinieerd, is de trainingsupdate met één commando uit te voeren en het resultaat al even snel te visualiseren:
spacy project run all
spacy project run visualize-model

Het goede nieuws is dat Apple nu wel wordt herkend als een bedrijf. Het systeem lijkt ook extra aandacht te hebben voor cijfers gevolgd door woorden, die in commerciële context wel eens een geldbedrag zouden kunnen zijn. Maar plots worden ook mensen en nationaliteiten aanzien als organisaties – en dat was vroeger niet zo. Wat is hier gebeurd?
{kind=link}
Het fenomeen staat bekend als Catastrophic Forgetting. In de ijver om de herkenning van een bepaalde categorie van entiteiten te verfijnen, zijn de andere entiteiten in het model bij het bijtrainen te ver naar de achtergrond gedrukt. De standaardoplossing is om ervoor te zorgen dat genoeg voorbeelden zijn toegevoegd in de trainingsdata die ook nog over alle andere entiteiten gaan. Je moet dus bijtrainen met een gezonde mix aan voorbeelden en zo ervoor zorgen dat je trainingsdata, ook als het enkel om een update gaat, goed gebalanceerd blijven.
Zelf aan de slag met NER trainen
Naast het updaten van een NER component kan je hem ook integraal vervangen door een andere die je zelf traint. Misschien vind je de 17 entiteiten aangeboden in de huidige trainingsdata overkill, en heb je genoeg aan wat bijvoorbeeld het Duitse taalmodel biedt: Person, Organisation, Location en Miscellaneous, zoals gedefinieerd in de WikiNER dataset, en die ook beschikbaar is voor het Nederlands en het Frans.
Dan doe je exact hetzelfde als voordien, maar je haalt de mosterd bij het kant-en-klare SpaCy WikiNER project dat je ook eenvoudig kan klonen:
python -m spacy project clone pipelines/ner_wikiner
Dan is het een kwestie van de trainingsdata van WikiNER te downloaden en te converteren naar het juiste inputformaat. Die datavoorbereiding is waarschijnlijk nog het meeste werk. Eens het model getraind en bewaard is, kan je de NER-component ervan eenvoudig inpluggen in een andere analysepijplijn, op dezelfde manier waarop je een stukje toevoegt aan de Morphologizer.
Het wordt vooral interessant als je zelf nieuwe categorieën van entiteiten gaat definiëren. Er is immers geen reden om je te beperken tot dat wat voorzien is in een of andere dataset. Voor e-health toepassingen kan het zeer nuttig zijn om ziektes, behandelingen en medicijnen in een tekst als dusdanig te markeren. In biomedische tekst kan het gaan over namen van genen of proteïnen. En in juridische tekst is de herkenning van wetsartikelen ongetwijfeld ook nuttig.
Zolang je er trainingsdata voor kan aanmaken, en je zorgt dat er een goede balans is tussen alle entiteiten die je wil herkennen, is het allemaal mogelijk. Met wetsartikelen hadden we dat bij Smals Research al eens uitgeprobeerd, met het oog op entity linking – in dit geval, linken naar de eigenlijke wettekst via de ELI:

Conclusie
Er is vandaag nog wat achterstand wat betreft Nederlandstalige NLP. Het ontbreken van grote trainingsdatasets zet een rem op de performantie, maar met de opkomst van transformer modellen, ook in het Nederlands, kan in de nabije toekomst zeker verbetering worden verwacht.
Ondertussen zijn de bestaande taalmodellen misschien niet perfect, maar zeker niet slecht. Ze zijn bovendien erg gemakkelijk om te tweaken en te optimaliseren voor eigen toepassingen. Wie vandaag al begint met computationele analyse van taal, zal dus gemakkelijk kunnen meesurfen met de opeenvolgende verbeteringen die de komende maanden en jaren zichtbaar zullen zijn.
Nederlandstalige Datasets Lassy, Alpino en OntoNotes
Lassy heeft haar oorsprong in de academische wereld van de computationeel taalkundigen. Er bestaat een kleine versie en een grote versie: LassyKlein met ongeveer 1 miljoen woorden, is manueel geverifieerd; LassyGroot met ongeveer 700 miljoen woorden, is automatisch geannoteerd met het programma Alpino . Er werd een eigen XML-annotatieformaat gebruikt, geïnspireerd op het eerdere project Corpus Gesproken Nederlands. Dit formaat verschilt nogal van het CoNLL formaat dat vaak gebruikt wordt voor opslag van dit soort gegevens, en dat de standaard is voor de Universal Dependencies datasets. Na omzetting met een convertor kon wel een subset van LassyKlein daarin opgenomen worden als UD_Dutch-LassySmall. Enkel een subset uit Wikipedia is echter bewaard, met daarin 7.388 zinnen van in totaal 98163 woorden.
Een andere dataset gebaseerd op voornamelijk nieuwsartikels is ook beschikbaar: UD_Dutch-Alpino, met daarin 13.578 zinnen met 208601 woorden. Wie enkele van de zinnen leest, merkt dat ze vooral verzameld zijn in de vroege jaren 2000. Onderwerpen die ter sprake komen zijn bijvoorbeeld Brussel-Halle-Vilvoorde, Justine Henin-Hardenne en Wim Kok als premier van Nederland.
OntoNotes 5.0 is het Engelstalige bronmateriaal voor SpaCy’s grammaticale analyse. Het bevat naar schatting 2 miljoen woorden in +/- 300.000 zinnen uit gevarieerde bronnen: het merendeel uit nieuwsartikels waarvan een deel ook uit vertaalde internationale bronnen, en dan nog een klein deel uit blogs en stukken uit de Bijbel. De dataset kan gezien worden als een opvolger van de Penn Treebank , een van de eerste grote datasets voor automatische syntactische analyse. Ook OntoNotes is niet in het CoNLL formaat en vereist dus een omzetting. Om een model te kunnen trainen, moet SpaCy de CoNLL-data nog converteren in haar eigen interne formaat.
Meer weten over NLP in het Nederlands? Op 31 maart 2021 was Joachim Ganseman te gast bij Infosecurity:
Wie meer wil lezen over NLP in het algemeen, kan daarvoor terecht op de blog van Smals Research:
- Facetten van Natural Language Processing: deel 1 & deel 2
- API’s voor computervertaling – de praktijk
- NLP & Modèles de langue (Franstalig)
- Named Entity Recognition: une application pratique du NLP (Franstalig)
Dit is een ingezonden bijdrage van Joachim Ganseman, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.