
Kunnen we binnenkort op reis moeiteloos communiceren met de lokale bevolking dankzij een AI-tolk? Zal een AI-toepassing tv-programma’s live ondertitelen of tijdens internationale vergaderingen simultaan vertalen? Al meerdere techreuzen, zoals Google, gooiden hoge ogen met hun tolk-apps. Hoe werkt zo’n app en waarom is real-time tolken nog niet voor meteen?
Snel een tekst vertalen is de laatste jaren kinderspel geworden dankzij Google Translate, Deepl of de eTranslation tool van de EU voor publieke administraties. Zeker als de vertaling niet volledig accuraat hoeft te zijn, zijn deze tools handig.
Voor professionele vertalers verandert de snelle opkomst van zulke technologieën hun jobinhoud. Naast al bestaande hulpmiddelen, zoals vertaalgeheugens waarmee eerdere vertalingen hergebruikt kunnen worden, treden nu ook vertaalmotoren gebaseerd op neurale netwerken op de voorgrond. Zo verschuift de taak van de vertaler meer richting revisie: nalezen en corrigeren op vlakken waar vertaalmotoren nog struikelen. Denk bijvoorbeeld aan homoniemen, spreekwoorden, woordspelingen, emotionele nuance, culturele referenties, enz.
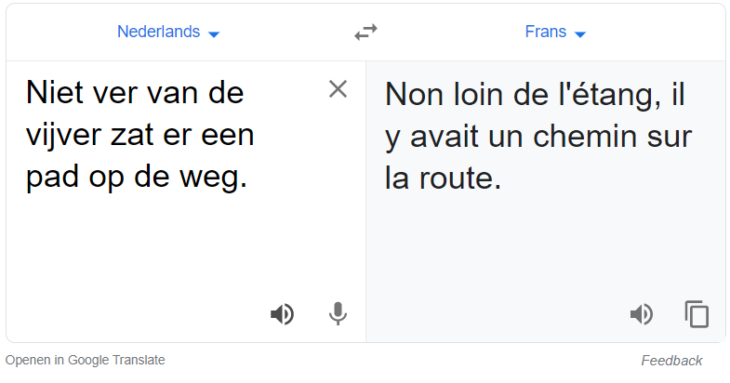
De huidige AI-tolk
Nog een stuk complexer is simultaan vertalen, zoals tijdens een internationale vergadering of diplomatiek overleg. De benodigde vaardigheden zijn zodanig verschillend dat zelfs de opleidingen tot tolk en vertaler fundamenteel anders ingericht worden. Tolken werken bijvoorbeeld onder zeer hoge tijdsdruk: een vertaling moet bijna in real-time geproduceerd worden. Toekomstige context of verduidelijkingen kunnen nog ontbreken op het moment van vertalen. Tolken gebeurt om die reden eerder op een “best effort” basis.
Om bestaande text-to-text vertaalmotoren te gebruiken om bijvoorbeeld debatten op tv in real-time te ondertitelen, moet eerst spraak correct naar tekst worden omgezet. Hier spelen speech-to-text engines een rol, maar die hebben hun beperkingen. Google gooide dan ook hoge ogen toen ze de Interpreter modus van Google Translate voorstelden. Deze is ondertussen naadloos ingewerkt in smart speakers en mobiele apps met Google Assistant. Microsoft volgde op de voet met hun Translator, die ook vergaderingen met anderstalige personen kan begeleiden. Naast hun AI-tolk lanceerden ze plug-ins voor, onder andere, PowerPoint, waarmee een presentatie live ondertiteld kan worden in een andere taal als de spreker duidelijk articuleert en standaardtaal hanteert.
Een blik achter de schermen: hoe werkt computergestuurd tolken?
Zo goed als al deze tolk-apps werken momenteel in dialoogvorm. Het systeem wacht met vertalen tot een zin volledig is uitgesproken. Een belangrijke motivatie hiervoor is het verschil in woordvolgorde tussen talen: het einde van een zin in de ene taal vormt soms het begin van de zin in de andere taal. Neem dit voorbeeld, vertaald met Deepl:
- Ik ben afgelopen zaterdag nog snel even naar Antwerpen gegaan.
- Je me suis rendu rapidement à Anvers samedi dernier.
Om vertraging of latency zoveel mogelijk te vermijden, kan de vertaling al worden gestart nog voor de zin helemaal is uitgesproken, maar dan moet de optie er zijn om de vertaling achteraf nog aan te passen. Bij een machinevertaling van een tekst is post-editing sowieso sterk aan te raden en eenvoudig te realiseren – zelfs deels automatisch. Bij simultaan vertalen zal er een afweging gemaakt moeten worden: hoe minder latency, hoe groter het risico dat de vertaalde woorden meermaals herwerkt moeten worden.
Achter de schermen doen Automatic Speech Recognition engines dit al bij de transcriptie van de audio. Al naargelang er bijkomende fonemen worden herkend, wordt telkens herberekend wat het meest waarschijnlijke woord is dat uitgesproken wordt. Bij elke automatische transcriptie van audio of bij ondertiteling, zijn ook segmentatie en filtering, zoals het weglaten van “euh” en andere stopwoorden, belangrijke problemen die in een editing-fase opgelost moeten worden. Ook herhalingen zijn erg courant in natuurlijke spraak maar niet wenselijk in de vertaling. Verder moeten bepaalde entiteiten, zoals eigennamen of datums, correct herkend worden. Microsoft vatte dat alles samen in het volgende diagram van een speech-to-speech vertaalsysteem:
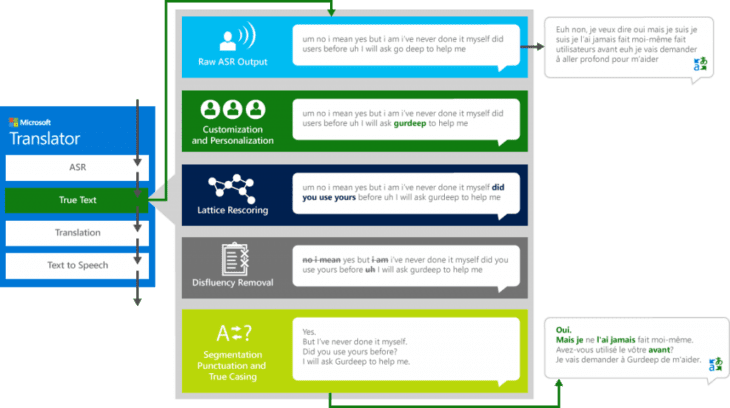
AI-tolken in de praktijk
Er zijn al heel wat veelbelovende concepten uitgewerkt om de AI-tolk te realiseren, zoals deze automatische ondertitelaar/vertaler voor hoorcolleges op de universiteit. Een demofilmpje van het systeem vind je hier. Je ziet er duidelijk de automatische post-editing aan het werk, waardoor de vertaling regelmatig een update krijgt. Dit kan moeilijk te volgen zijn voor de gebruiker wanneer dit vaak gebeurt. Het klaslokaal is een relatief ideale omgeving voor dit soort toepassing: een professor zal doorgaans duidelijk articuleren, standaardtaal hanteren en het publiek komt weinig tussen. Maar zelfs dan zijn er nog allerlei obstakels te overwinnen.
Waar de technologie vandaag staat, in een minder ideale omgeving en met Nederlands als brontaal, wordt duidelijk bij de automatische ondertiteling van dit filmpje op YouTube. Schakel automatische ondertiteling voor een andere taal in via de opties Instellingen > Ondertiteling > Automatisch vertalen (auto-translate). Fouten bij de initiële spraaktranscriptie leiden hier duidelijk tot bijkomende fouten in de vertaling, waar de coherentie van de zin plots soms helemaal zoek is of zelfs grote delen wegvallen. Het gebruik van dialect zorgt in de automatische vertaling van dit filmpje al helemaal voor een onzinnig resultaat.
Er wordt actief academisch onderzoek gedaan naar end-to-end speech-to-text vertaling, waarbij spraak in de brontaal vertaald wordt naar tekst in de doeltaal. De resultaten benaderen stilaan die van cascade-systemen, waarbij de vertaling apart volgt na de spraakherkenning in plaats van tegelijkertijd binnen één systeem. Om tot betere vertalingen te komen, zijn er echter grote hoeveelheden geannoteerde data nodig, wat de evolutie hiervan vertraagt. Ook het evalueren van vertaalmotoren is onderwerp van debat: wanneer is een vertaling objectief beter dan een andere? Hier vind je een uitgebreide introductie van dit onderwerp.
Er bestaan ondertussen kleinere hulpmiddelen die specifieke deelproblemen van het tolken aanpakken. Deze focussen bijvoorbeeld op de onmiddellijke herkenning van individuele woorden, terwijl iemand spreekt. InterpretBank is zo’n hulpmiddel dat jargon of andere moeilijke terminologie detecteert en onmiddellijk de correcte vertaling voorstelt aan de simultaanvertaler. Deze hoeft dan geen specialist meer te zijn in het gespreksonderwerp en krijgt zo meteen de juiste vertaling van vakjargon.
Conclusie
Op dit moment zijn de meest robuuste methodes voor speech-to-speech vertaling de cascade-systemen. Het probleem van een andere woordvolgorde is fundamenteel. Er zal bijna altijd een vertraging van een zinslengte moeten worden toegestaan om tot een robuuste vertaling te komen, waarbij achteraf geen grote aanpassingen meer nodig zijn. Ook in de nabije toekomst zal volautomatisch tolken nog wel een tijdje in dialoogvorm blijven. Hoe sneller de vertaling in real-time moet volgen, hoe meer fouten er getolereerd moeten worden. Wie zelf aan de slag wil met componenten voor spraakherkenning, post-editing en machine translation, kan de zoektocht beginnen bij projecten zoals Mozilla Deepspeech, CMUSphinx of MarianNMT. Datasets om vertaalmotoren te trainen zijn dan weer te vinden op bijvoorbeeld OpenSLR.org.
De auteur wenst Joan Van Poelvoorde, vertegenwoordiger RSZ bij de federale G-clouddienst Babelfed, en prof. dr. Bart Defrancq, hoofd van de tolkopleidingen van de UGent, te bedanken voor hun waardevolle input in de aanloop naar het schrijven van dit artikel.
Dit is een ingezonden bijdrage van Joachim Ganseman van Smals Research. Via deze link vind je meer informatie over de het onderzoek van de organisatie. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.