
Op 20 maart hield Amazon Web Services (AWS) een dag voor ontwikkelaars in het Gooiland in Hilversum. Tijdens deze Dev Day werden ontwikkelaars in drie tracks bijgepraat over waar AWS zoal mee bezig is. Deelnemers konden kiezen uit Serverless, Containers en AI. Wij zijn naar Hilversum gereden om met Julien Simon, AI Evangelist EMEA van AWS, te spreken over – je raadt het al – AI.
Simon mag dan een evangelist zijn, je kunt hem niet betrappen op zweverige praat. Hij vindt het belangrijk om over te brengen dat AI absoluut geen zwarte magie is. Uit de verschillende series en films die je voorbij ziet komen, zou je dat wellicht wel denken. Het is uiteindelijk een technologie die ingezet kan worden om bepaalde (business-) processen beter te laten verlopen. Meer is het op dit moment niet.

Verder benadrukt hij tijdens zijn sessie in Hilversum, waar tussen de 100 en 200 ontwikkelaars op af zijn gekomen, dat AI ook niet moeilijk is. Het is niet meer dan wat wiskunde en een beetje code gekoppeld aan siliconen. Uiteindelijk komt er veel meer engineering bij kijken dan wetenschap. De wetenschap die wordt gebruikt zorgt echter ook zeker voor de nodige hoofdbrekens, zoals we verderop zullen zien.
Wat bedoelen we met AI?
Voor we verdergaan, willen we voor de zekerheid nog maar eens het onderscheid maken tussen termen die vaak op een hoop gegooid worden. We hebben dit ook al eens gedaan in ons interview met David Carmona van Microsoft, maar het is goed om dit onderscheid af en toe te herhalen.
AI is de overkoepelende term waar de andere zaken onder vallen. Artificial Intelligence is overigens geen jonge tak binnen de (computer-)wetenschap. Je kunt het ontstaan ervan volgens Simon zelfs vrij nauwkeurig dateren. En wel in 1956, toen een groep computerwetenschappers voor het eerst aan de slag ging met het ontwikkelen van computers die zich gedragen als mensen.
AI op zich betekent echter niets. Het gaat om de bouwstenen die het mogelijk maken. Allereerst is er uiteraard machine learning, volgens Simon op dit moment een van de belangrijkste onderdelen van AI. De reden hiervoor is onder andere dat het al veel gebruikt wordt. In de basis is machine learning niet meer dan het toepassen van algoritmes op een dataset. Uiteraard is de kwaliteit van de data belangrijk en heb je er genoeg van nodig.

Machine learning en deep learning
Machine learning is echter een tamelijk dom proces, dat je precies moet vertellen wat je moet doen in bepaalde gevallen. Is het eenmaal goed getraind, dan kan het taken vele malen sneller uitvoeren dan mensen. Te veel data is niet gunstig voor machine learning, daar kan het geen wijs meer uit op den duur. Heb je een machine learning algoritme getraind om verkeersdrukte te monitoren, om op basis daarvan bepaalde acties voor een bepaalde stad uit te voeren, dan moet je niet de data voor heel Nederland aanbieden. De kans dat je verkeerde uitkomsten krijgt, is dan erg groot.
Deep learning maakt gebruik van neurale netwerken, die tot op zekere hoogte zelfstandig kunnen functioneren. Die ‘weten’ op welke data ze wel en op welke data ze niet moeten letten. Volgens Simon is deep learning bijzonder geschikt voor het verwerken van beeld. Hij geeft het Chinese TuSimple als voorbeeld. Dat bedrijf heeft een vrachtwagen ontwikkeld die volledig autonoom kan rijden. Die vrachtwagen heeft er inmiddels al een succesvolle eerste rit van zo’n 300 kilometer opzitten. Hiervoor is het Apache MXNet deep learning framework gebruikt. Het trainen van het neurale netwerk bestaat uit het voeden ervan met uren en uren aan video. Een neuraal netwerk weet na verloop van tijd dat het niet iedere pixel hoeft te analyseren, maar dat het op bepaalde zaken moet letten. Naast belijning kun je ook denken aan verkeerslichten, zebrapaden en dergelijke.
Dat zelfrijdende voertuigen nog niet uitontwikkeld zijn, werd eerder deze week overigens pijnlijk duidelijk, toen er in de VS iemand werd doodgereden door een zelfrijdende auto.
SageMaker
Gevraagd naar zijn favoriete aankondiging tijdens AWS re:invent afgelopen november, aarzelt Simon geen moment. Dat is zonder twijfel SageMaker, een machine learning managed service die het leven van ontwikkelaars en datawetenschappers een stuk eenvoudiger moet maken. Het doel van deze dienst is vooral om machine learning beter te schalen. Dat is namelijk de voornaamste uitdaging waar veel mensen die met machine learning aan de slag gaan, tegenaan lopen. Om het in de woorden van Simon te zeggen: “SageMaker overbrugt de Grand Canyon tussen data science en productie”.
SageMaker roept een API op, zegt waar de data staan en waar ze heen moeten. Daarna kun je de data met een enkele API-call deployen waar je maar wil. Je ziet tijdens het testen van de instellingen ook precies hoe het eindresultaat er in de praktijk uit gaat zien. Dat is ook een sterk onderdeel van de dienst, volgens Simon.
Als voorbeeld van waar SageMaker voor gebruikt kan worden, noemt Simon Digital Globe. Dit bedrijf heeft niet minder dan 100 petabyte aan satellietbeelden. Dit is opgeslagen bij Amazon in S3. Om dit te krijgen moest er trouwens gebruikgemaakt worden van de Snowmobile, de vrachtwagen die AWS in kan zetten als het overzetten via het internet te lang duurt. Digital Globe was volgens Simon zelfs de eerste klant van de Snowmobile.
Het probleem waar Digital Globe tegenaan liep, was dat S3-opslag weliswaar erg goed presteert, maar ook erg prijzig is. Dit terwijl een groot gedeelte van de satellietbeelden helemaal niet zo relevant en maar zelden nodig zijn. Denk bijvoorbeeld aan het midden van de Grote Oceaan of Antarctica. Dat soort beelden kunnen dan beter in het goedkopere Glacier opgeslagen worden bij AWS. Dat is zo’n vijf tot zes keer goedkoper. Zeker als je dergelijke hoeveelheden data hebt, kan dat behoorlijk aantikken. Met SageMaker heeft Digital Globe door middel van een machine learning algoritme bepaald welke beelden naar Glacier moeten en welke niet. Dit heeft voor 50 procent minder kosten gezorgd.
AI is niet bijster slim
AI ontlokt her en der apocalyptische scenario’s bij mensen. We worden overgenomen door kunstmatige intelligenties, die vele malen intelligenter zijn dan wij. Volgens Simon zal dat zo’n vaart niet lopen. Zelfs een goede AI is op dit moment nog helemaal niet zo intelligent. Je kunt de taken die een AI op dit moment goed kunt een beetje vergelijken met wat een vijfjarige goed kan. Vraag een een AI om uit een set van afbeeldingen de honden te selecteren, dan kan hij dat, mits hij erop getraind is. Vraag je hem iets anders, dan snapt hij er niets van. Hetzelfde geldt voor machine learning-gebaseerde vertalingen. Heb je een algoritme dat Engels naar Nederlands kan vertalen, dan kan datzelfde algoritme nagenoeg niets met andere talen. Het grote verschil met mensen is dat een kunstmatige intelligentie het vele malen sneller kan en dat hij er veel meer kan doen.
Over SGD en Saddle Points
Zoals eerder aangehaald, zijn we ook bij de sessie van Simon geweest tijdens de Dev Day. Daar gaf hij in een zogeheten deep dive een inleiding in AI voor de aanwezige developers. Hij begint die sessie met de eveneens al aangehaalde uitspraak dat AI in de basis niet moeilijk is. Daarna wordt echter ook duidelijk dat er wel degelijk uitdagingen zijn als je als developer aan de slag gaat met AI. Bij wijze van afsluiting van dit artikel, gaan we daar kort even op in.
Zo loop je aan tegen het zogeheten Stochastic Gradient Descent-fenomeen aan. Als je in onderstaande figuur van het hoogste naar het laagste punt wilt, mogen de stappen niet te groot maar ook niet te klein zijn. Ze moeten zo groot zijn dat je zowel het stijgen van de waarde als het dalen van de waarde moet kunnen vastleggen. Is de stap te groot, dan stap je zomaar van de ene piek naar de andere. Is hij te klein, dan kun je heel lang doelloos rondzwerven.
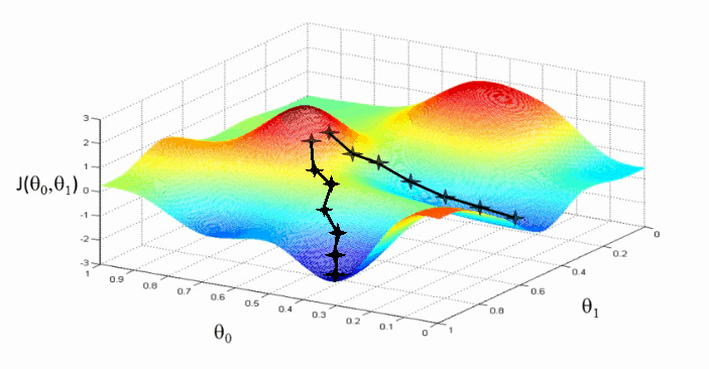
Bron: www.machinelearningpython.org
Simon geeft aan dat er geen mogelijkheid is om te voorspellen of je bij een gegeven laagste punt ook daadwerkelijk het allerlaagste punt bereikt hebt. Uiteindelijk komt het erop neer dat je een algoritme voldoende keren door de dataset laat gaan, dat je een zo laag mogelijk punt bereikt. Er kan dan altijd nog een lager punt zijn, maar je kunt ook meerdere keren bij hetzelfde laagste punt komen. Dat weet je eenvoudigweg niet.
Een ander fenomeen dat Simon aanstipt, zijn de zogeheten Saddle Points, waarvan je hieronder een weergave ziet. Voor zover wij het hebben begrepen is dit ook een vorm van SGD. Het punt hier is dat je tegelijkertijd op het laagste en hoogste punt kunt zitten, afhankelijk van welke as je bekijkt. Uiteraard ‘zie’ je dat niet, want je bent bezig met een set abstracte data. Ook dit kun je alleen afvangen door het algoritme voldoende keren aan de slag te laten gaan met de data.
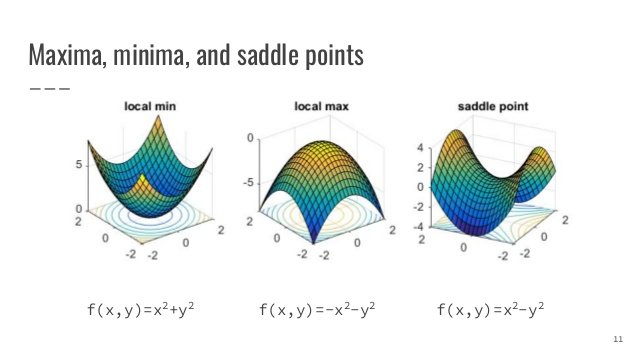
Bron: www.slideshare.net